

Hurtownia danych: fundament data-driven business
W dzisiejszym świecie biznesu dane są nową ropą naftową – cennym zasobem, który napędza innowacje, wzrost i przewagę konkurencyjną. Jednak samo posiadanie danych to za mało. Firmy toną w informacjach pochodzących z dziesiątek systemów: CRM, ERP, platform e-commerce, mediów społecznościowych czy urządzeń IoT. Te dane są często rozproszone, niespójne i trudne do analizy w czasie rzeczywistym. Problem ten rozwiązuje hurtownia danych (Ang. Data Warehouse, DWH) – centralny filar strategii analitycznej każdej nowoczesnej organizacji, która aspiruje do miana „data-driven”. To nie tylko technologiczny buzzword, ale strategiczna inwestycja, która przekształca surowe dane w potężną wiedzę biznesową.
Czym więc jest to potężne narzędzie? W najprostszych słowach, hurtownia danych to centralny, zintegrowany repozytorium danych historycznych, zaprojektowany specjalnie do celów analitycznych i raportowych. To swoista „biblioteka” firmowej wiedzy, gdzie informacje z różnych źródeł są starannie gromadzone, porządkowane, czyszczone i udostępniane w sposób, który umożliwia szybkie i efektywne zadawanie skomplikowanych pytań. W tym artykule zgłębimy, czym dokładnie jest hurtownia danych, jak funkcjonuje jej skomplikowany ekosystem i dlaczego stała się absolutnie kluczowym elementem dla firm dążących do podejmowania świadomych, opartych na faktach decyzji.
Czym dokładnie jest hurtownia danych? Architektura i kluczowe cechy
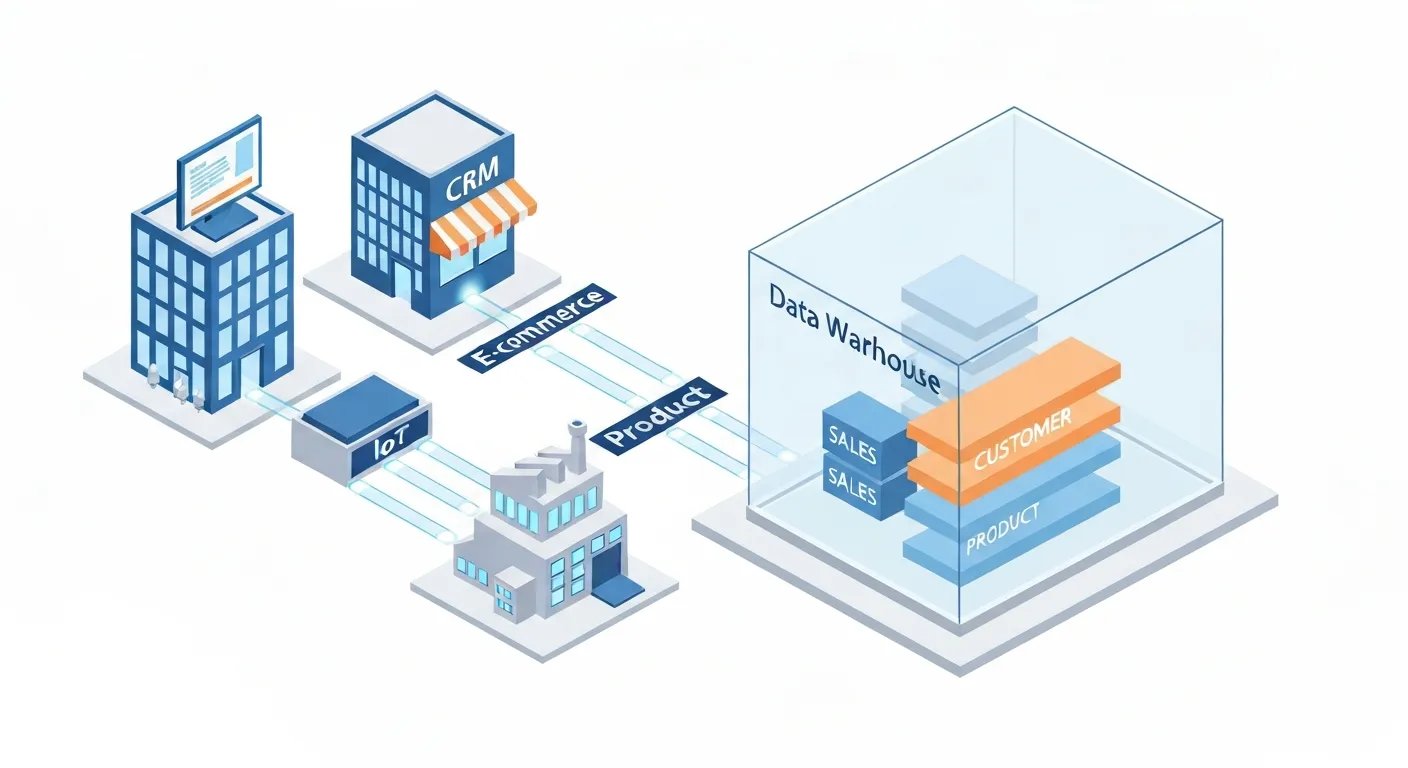
Aby w pełni zrozumieć koncepcję hurtowni danych, należy odróżnić ją od operacyjnej bazy danych, która służy do bieżącej obsługi aplikacji (np. Sklepu internetowego czy systemu rezerwacji). Baza danych jest zoptymalizowana pod kątem szybkich, prostych transakcji (zapis, odczyt, modyfikacja pojedynczych rekordów), podczas gdy hurtownia danych Jest stworzona do analizy ogromnych wolumenów danych historycznych. Jej architektura i zasady działania opierają się na czterech fundamentalnych cechach, zdefiniowanych przez Billa Inmona, uważanego za ojca tej koncepcji:
- Zorientowana na temat (Subject-Oriented): Dane w hurtowni są organizowane wokół kluczowych obszarów biznesowych, takich jak „Klient”, „Produkt”, „Sprzedaż” czy „Finanse”. Zamiast skupiać się na procesach operacyjnych (jak w bazach danych), hurtownia integruje wszystkie informacje dotyczące danego tematu, tworząc jego kompleksowy obraz. Pozwala to na analizę np. Całego cyklu życia klienta, a nie tylko pojedynczej transakcji.
- Zintegrowana (Integrated): To jedna z najważniejszych cech. Hurtownia danych pobiera informacje z wielu, często heterogenicznych systemów źródłowych. W procesie integracji dane te są ujednolicane. Oznacza to standaryzację nazw, formatów, jednostek miar i kodów. Na przykład, dane klienta z systemu CRM, gdzie adres zapisano jako „ul. Marszałkowska”, i z systemu fakturowego, gdzie widnieje „Marszałkowska”, zostaną sprowadzone do jednego, spójnego formatu. Eliminuje to chaos i zapewnia, że analizy opierają się na wiarygodnych informacjach.
- Niezmienna w czasie (Time-Variant): Hurtownia danych jest repozytorium historycznym. Dane, raz załadowane, nie są usuwane ani nadpisywane. Każdy rekord jest opatrzony znacznikiem czasu, co pozwala na analizę trendów, porównywanie okresów i śledzenie zmian w czasie. Możemy zapytać nie tylko „jaki jest obecny stan magazynowy?”, ale także „jak zmieniał się stan magazynowy tego produktu w każdym kwartale na przestrzeni ostatnich pięciu lat?”.
- Trwała (Non-Volatile): Ta cecha jest ściśle powiązana z poprzednią. „Non-volatile” oznacza, że dane w hurtowni są stabilne. Po załadowaniu i przetworzeniu, informacje służą wyłącznie do odczytu i analizy. Nie przeprowadza się na nich bieżących operacji modyfikacji czy usuwania, co gwarantuje stabilność i spójność historycznych analiz. Nowe dane są po prostu dodawane, rozbudowując historyczny obraz działalności firmy.
Architektura typowej hurtowni danych składa się z kilku warstw. Na samym dole znajdują się systemy źródłowe. Następnie mamy warstwę przejściową (staging area), gdzie dane są tymczasowo składowane przed przetworzeniem. Kluczowym elementem jest proces ETL (Extract, Transform, Load), o którym więcej za chwilę. Wreszcie, w sercu systemu znajduje się sama hurtownia danych, z której korzystają narzędzia analityczne i raportowe, takie jak platformy Business Intelligence (np. Tableau, Power BI) czy narzędzia dla data scientistów.
Jak działa hurtownia danych: proces od surowych danych do wartościowej wiedzy
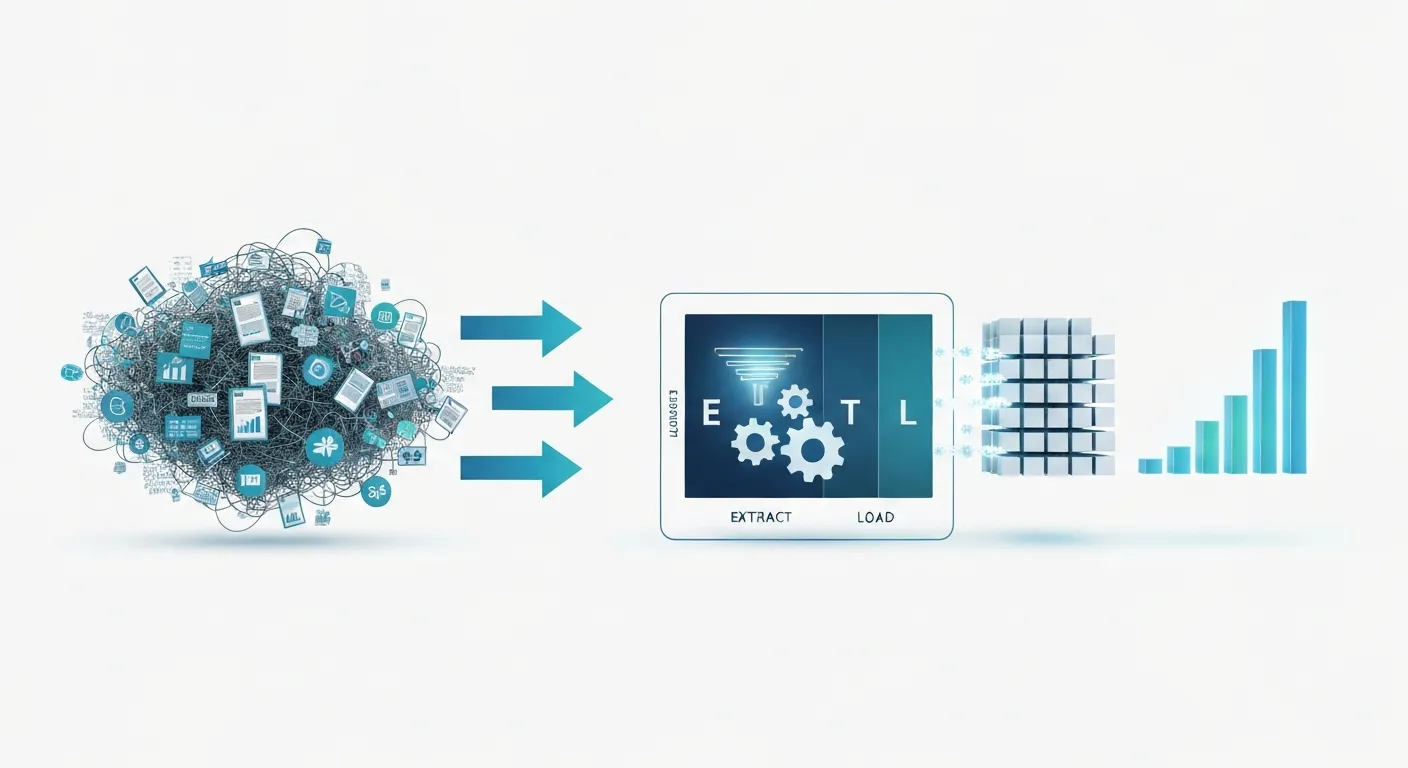
Stworzenie użytecznej hurtowni danych to skomplikowany proces inżynieryjny, który przekształca chaotyczne, surowe dane w uporządkowany i wartościowy zasób. Sercem tego procesu jest mechanizm znany jako ETL (Extract, Transform, Load), Czyli Ekstrakcja, Transformacja i Ładowanie. Coraz częściej stosuje się również jego wariant, ELT (Extract, Load, Transform), Popularny w rozwiązaniach chmurowych.
Krok 1: Ekstrakcja (Extract)
Wszystko zaczyna się od pozyskania danych z różnorodnych systemów źródłowych. Mogą to być:
- Systemy transakcyjne (OLTP): Bazy danych systemów CRM, ERP, SCM.
- Pliki płaskie: Arkusze kalkulacyjne (CSV, Excel), pliki logów serwerów.
- Dane z aplikacji webowych i mobilnych: Analityka internetowa (np. Google Analytics).
- Dane z mediów społecznościowych i zewnętrznych API.
- Dane z urządzeń IoT: Sensory, maszyny produkcyjne.
Na tym etapie kluczowe jest zidentyfikowanie wszystkich istotnych źródeł i zapewnienie regularnego, zautomatyzowanego pobierania z nich danych – zazwyczaj w określonych odstępach czasu (np. Co noc).
Krok 2: Transformacja (Transform)
To najbardziej złożony i kluczowy etap, w którym „brudne” dane zamieniają się w „czyste” i spójne informacje. Proces transformacji obejmuje szereg operacji:
- Czyszczenie (Cleansing): Identyfikacja i poprawianie błędów, usuwanie duplikatów, uzupełnianie brakujących wartości (np. Zastępowanie pustego pola domyślną wartością).
- Standaryzacja (Standardization): Ujednolicanie formatów, np. Konwersja wszystkich dat do formatu RRRR-MM-DD, standaryzacja adresów czy nazwisk.
- Integracja (Integration): Łączenie danych z różnych źródeł. Na przykład, dane o sprzedaży produktu z systemu e-commerce są łączone z danymi o jego koszcie z systemu ERP, aby umożliwić analizę rentowności.
- Agregacja (Aggregation): Wstępne obliczanie podsumowań, takich jak suma sprzedaży dziennej, średnia wartość koszyka czy liczba unikalnych klientów. Pre-agregacja danych znacząco przyspiesza późniejsze zapytania analityczne.
Krok 3: Ładowanie (Load)
Po zakończeniu transformacji, czyste i ustrukturyzowane dane są ładowane do centralnego repozytorium, czyli właściwej hurtowni danych. Proces ten może odbywać się na dwa główne sposoby: pełne ładowanie (cały zbiór danych jest zastępowany nowym) lub, co jest znacznie częstsze i wydajniejsze, ładowanie przyrostowe (do hurtowni dodawane są tylko nowe i zmienione rekordy od czasu ostatniego ładowania).
W modelu ELT Kolejność jest inna: surowe dane są najpierw ładowane (Load) do hurtowni (często do tzw. Data Lake), a dopiero potem, z wykorzystaniem mocy obliczeniowej samej hurtowni, poddawane są transformacji (Transform). Takie podejście jest charakterystyczne dla nowoczesnych, chmurowych hurtowni danych jak Google BigQuery czy Snowflake, które dysponują ogromną mocą obliczeniową.
Hurtownia danych a baza danych: kluczowe różnice
Jednym z najczęstszych nieporozumień jest mylenie hurtowni danych ze zwykłą bazą danych. Choć obie przechowują dane, ich cel, struktura i sposób działania są fundamentalnie różne. Zrozumienie tych różnic jest kluczowe, by docenić unikalną wartość, jaką wnosi hurtownia danych.
Cel i zastosowanie
- Baza danych (OLTP – Online Transaction Processing): Jej głównym celem jest obsługa bieżących operacji biznesowych. Jest zoptymalizowana pod kątem szybkiego przetwarzania dużej liczby małych, prostych transakcji (np. Dodanie produktu do koszyka, zapisanie nowego klienta, aktualizacja stanu magazynowego). Priorytetem jest szybkość zapisu i integralność danych transakcyjnych.
- Hurtownia danych (OLAP – Online Analytical Processing): Została zaprojektowana do analizy. Jej celem jest obsługa skomplikowanych, wielowymiarowych zapytań na ogromnych zbiorach danych historycznych. Priorytetem jest szybkość odczytu i agregacji danych, aby analitycy mogli sprawnie generować raporty i odkrywać trendy.
Struktura danych
- Baza danych: Zazwyczaj jest znormalizowana. Oznacza to, że dane są podzielone na wiele małych, połączonych ze sobą tabel, aby uniknąć redundancji (powtarzania informacji). Taka struktura jest idealna do operacji zapisu i modyfikacji.
- Hurtownia danych: Często jest zdenormalizowana. Stosuje się w niej modele takie jak schemat gwiazdy (star schema) lub płatka śniegu (snowflake schema), gdzie jedna centralna tabela faktów (np. O sprzedaży) jest otoczona przez tabele wymiarów (np. Czas, produkt, klient). Taka struktura, choć zawiera redundancje, jest znacznie wydajniejsza dla skomplikowanych zapytań analitycznych.
Zakres danych
- Baza danych: Przechowuje głównie dane bieżące, aktualne. Starsze dane mogą być archiwizowane lub usuwane, aby utrzymać wydajność systemu.
- Hurtownia danych: Jej esencją są dane historyczne. Gromadzi informacje z wielu lat, co jest niezbędne do analizy trendów, sezonowości i długoterminowych wzorców.
Rodzaje hurtowni danych: od on-premise do chmury
Podobnie jak inne technologie, hurtownie danych ewoluowały na przestrzeni lat. Dziś firmy mogą wybierać spośród kilku modeli wdrożeniowych, z których każdy ma swoje wady i zalety.
Tradycyjna hurtownia danych (On-Premise)
To klasyczne podejście, w którym cała infrastruktura – serwery, pamięć masowa, oprogramowanie – znajduje się fizycznie w centrum danych firmy. Organizacja ma pełną kontrolę nad sprzętem, bezpieczeństwem i danymi. Jednakże model ten wiąże się z wysokimi kosztami początkowymi (CAPEX), koniecznością utrzymywania wyspecjalizowanego zespołu IT oraz ograniczoną skalowalnością. Rozbudowa mocy obliczeniowej czy przestrzeni dyskowej jest kosztowna i czasochłonna.
Chmurowa hurtownia danych (Cloud Data Warehouse)
To obecnie dominujący trend. Rozwiązania takie jak Amazon Redshift, Google BigQuery, Snowflake Czy Azure Synapse Analytics Oferują hurtownię danych jako usługę w chmurze. Główne zalety to:
- Elastyczność i skalowalność: Moc obliczeniową i przestrzeń na dane można zwiększać lub zmniejszać niemal natychmiast, płacąc tylko za faktyczne zużycie.
- Niższy koszt wejścia: Brak konieczności inwestowania w drogą infrastrukturę (przesunięcie z CAPEX na OPEX).
- Zarządzanie przez dostawcę: Kwestie takie jak utrzymanie sprzętu, aktualizacje czy backupy są po stronie dostawcy chmury, co odciąża wewnętrzne zespoły IT.
- Separacja mocy obliczeniowej od przechowywania: Nowoczesne platformy pozwalają niezależnie skalować zasoby do przetwarzania i zasoby do przechowywania danych, co optymalizuje koszty.
Chmurowa hurtownia danych Demokratyzuje dostęp do zaawansowanej analityki, czyniąc ją osiągalną nie tylko dla korporacji, ale również dla mniejszych firm.
Data Lake i Data Lakehouse: Nowoczesne ewolucje
Warto również wspomnieć o koncepcjach pokrewnych. Data Lake (jezioro danych) To repozytorium, które przechowuje ogromne ilości surowych danych w ich natywnym formacie. W przeciwieństwie do hurtowni, dane nie muszą być od razu ustrukturyzowane. Nowym podejściem jest Data Lakehouse, Czyli architektura hybrydowa, która łączy elastyczność Data Lake z funkcjami zarządzania i strukturą hurtowni danych, oferując jedno, zunifikowane rozwiązanie.
Dlaczego hurtownia danych jest kluczowa dla nowoczesnego biznesu?
Inwestycja w budowę i utrzymanie hurtowni danych nie jest celem samym w sobie. To środek do osiągnięcia konkretnych, mierzalnych korzyści biznesowych, które w dzisiejszym konkurencyjnym środowisku decydują o sukcesie lub porażce.
1. Jedno źródło prawdy (Single Source of Truth)
To najważniejsza korzyść. W firmach bez centralnego repozytorium analitycznego różne działy często pracują na własnych, niespójnych danych. Marketing może mieć inne dane o klientach niż sprzedaż, a finanse inne dane o przychodach niż logistyka. Prowadzi to do chaosu, sprzecznych raportów i podejmowania decyzji w oparciu o błędne przesłanki. Hurtownia danych, Dzięki procesowi integracji i standaryzacji, staje się jedynym, wiarygodnym i uzgodnionym źródłem informacji dla całej organizacji.
2. Lepsze i szybsze podejmowanie decyzji
Mając dostęp do spójnych i historycznych danych, menedżerowie mogą opierać swoje decyzje na faktach, a nie na intuicji. Hurtownia danych umożliwia zadawanie skomplikowanych pytań i szybkie uzyskiwanie odpowiedzi. Przykłady? „Które kampanie marketingowe przyniosły najwyższy zwrot z inwestycji w zeszłym kwartale?”, „Jaki jest profil demograficzny naszych najbardziej rentownych klientów?”, „Czy istnieje korelacja między pogodą a sprzedażą określonych produktów?”.
3. Głębokie zrozumienie klienta (Customer 360)
Integrując dane z CRM, transakcji e-commerce, interakcji z obsługą klienta i aktywności w mediach społecznościowych, firma może zbudować kompletny, 360-stopniowy obraz każdego klienta. Pozwala to na precyzyjną segmentację, personalizację oferty, przewidywanie rezygnacji (churn) i optymalizację całej ścieżki zakupowej klienta.
4. Zwiększona wydajność operacyjna
Analiza danych operacyjnych z hurtowni pozwala na identyfikację wąskich gardeł, optymalizację procesów i prognozowanie zapotrzebowania. Firma logistyczna może zoptymalizować trasy dostaw, sieć handlowa może lepiej zarządzać zapasami w poszczególnych sklepach, a zakład produkcyjny może przewidywać awarie maszyn i planować konserwację predykcyjną.
5. Przewaga konkurencyjna i innowacje
Firmy, które sprawnie wykorzystują swoje dane, są w stanie szybciej identyfikować nowe trendy rynkowe, odkrywać niezaspokojone potrzeby klientów i wprowadzać innowacyjne produkty lub usługi. Hurtownia danych jest fundamentem nie tylko dla Business Intelligence, ale także dla bardziej zaawansowanych zastosowań, takich jak uczenie maszynowe (Machine Learning) i sztuczna inteligencja (AI).
Podsumowanie: Hurtownia danych jako strategiczny zasób
W erze cyfrowej transformacji hurtownia danych Przestała być luksusem dostępnym tylko dla największych korporacji. Stała się strategiczną koniecznością dla każdej organizacji, która chce świadomie kształtować swoją przyszłość. To znacznie więcej niż tylko repozytorium danych – to silnik analityczny, który przekształca historyczne informacje w przewidywalną przyszłość. Poprzez stworzenie jednego, wiarygodnego źródła prawdy, umożliwia podejmowanie trafniejszych decyzji, optymalizację operacji i budowanie głębszych relacji z klientami.
Wdrożenie hurtowni danych jest złożonym projektem, wymagającym starannego planowania i inwestycji. Jednak korzyści płynące z posiadania solidnych fundamentów analitycznych są nie do przecenienia. W świecie, gdzie wygrywają najszybsi i najsprytniejsi, to właśnie zdolność do efektywnego wykorzystania danych decyduje o tym, kto zostanie liderem, a kto pozostanie w tyle. Hurtownia danych jest kluczem, który otwiera drzwi do prawdziwie inteligentnego biznesu.
Dodaj komentarz