

JavaScript SEO: Jak zapewnić widoczność dynamicznych stron w Google?
Współczesny internet jest dynamiczny, interaktywny i w dużej mierze napędzany przez JavaScript. Frameworki takie jak React, Angular czy Vue.js zrewolucjonizowały sposób, w jaki tworzymy i doświadczamy strony internetowe, przekształcając je w zaawansowane aplikacje webowe (Single Page Applications). Ta ewolucja przyniosła jednak ze sobą nowe, złożone wyzwania dla specjalistów od marketingu i SEO. Kiedyś wystarczyło, aby robot Google przeanalizował prosty plik HTML. Dziś musi on nie tylko pobrać kod, ale także go wykonać – czyli wyrenderować stronę – aby zobaczyć jej ostateczną treść. To właśnie w tym procesie kryje się sedno JavaScript SEO.
Problem jest realny: jeśli Google nie jest w stanie poprawnie zobaczyć treści, linków i metadanych na Twojej stronie, to z jego perspektywy one po prostu nie istnieją. Skutkuje to niższymi pozycjami w wynikach wyszukiwania, mniejszym ruchem organicznym i utraconymi szansami biznesowymi. Zrozumienie, jak wyszukiwarki radzą sobie z JavaScriptem i jak możemy im w tym pomóc, stało się kluczową kompetencją w arsenale nowoczesnego marketera i dewelopera. W tym kompleksowym przewodniku zagłębimy się w świat JavaScript SEO, Wyjaśniając mechanizmy renderowania, diagnozując najczęstsze problemy i przedstawiając konkretne, skuteczne rozwiązania, które pozwolą Twoim dynamicznym stronom zaistnieć i zdobywać czołowe pozycje w Google.
Czym jest JavaScript SEO i dlaczego jest tak ważne?
JavaScript SEO To dziedzina optymalizacji dla wyszukiwarek, która koncentruje się na zapewnieniu, że strony internetowe zbudowane w oparciu o JavaScript są w pełni dostępne, możliwe do zindeksowania i prawidłowo interpretowane przez roboty wyszukiwarek, w szczególności Googlebota. Innymi słowy, chodzi o to, by cała treść, nawigacja i kluczowe elementy strony, które są generowane dynamicznie, były widoczne dla Google tak samo, jak są widoczne dla użytkownika.
Aby zrozumieć wagę tego zagadnienia, musimy cofnąć się do podstaw. Tradycyjna strona internetowa opierała się na statycznym HTML. Kiedy użytkownik lub robot wchodził na stronę, serwer wysyłał gotowy, w pełni uformowany dokument HTML z całą treścią. Proces był prosty i przewidywalny. Nowoczesne aplikacje webowe (SPA – Single Page Applications) działają inaczej. Serwer często wysyła jedynie szkielet HTML (tzw. „shell”) oraz duży plik JavaScript. Dopiero przeglądarka użytkownika (lub robota) wykonuje ten kod, pobiera dane z API i dynamicznie „maluje” treść na ekranie.
Tu pojawia się kluczowe wyzwanie:
- Zależność od renderowania: W przeciwieństwie do statycznego HTML, gdzie treść jest dostępna od razu, w przypadku stron JS treść pojawia się dopiero po wykonaniu skryptów. Google musi więc nie tylko pobrać stronę, ale i uruchomić wirtualną przeglądarkę, aby zobaczyć finalny efekt.
- Zwiększone zużycie zasobów: Renderowanie JavaScript jest znacznie bardziej kosztowne obliczeniowo dla Google niż parsowanie prostego HTML. Każda strona trafia do kolejki renderowania, co może powodować opóźnienia w indeksacji.
- Potencjalne błędy: Skrypty mogą zawierać błędy, które uniemożliwią ich wykonanie. Mogą też być zależne od zasobów zewnętrznych, które są zablokowane lub niedostępne dla Googlebota. W takim scenariuszu Google nigdy nie zobaczy pełnej treści.
Zignorowanie zasad JavaScript SEO To prosta droga do katastrofy w wynikach organicznych. Nawet najlepiej zaprojektowana, najszybsza i najbardziej użyteczna aplikacja webowa nie przyniesie korzyści biznesowych, jeśli jej kluczowa treść pozostanie niewidoczna dla największej wyszukiwarki na świecie. Dlatego właśnie dbałość o ten aspekt jest dziś nie tyle dobrą praktyką, co absolutną koniecznością dla każdego serwisu, który polega na technologiach dynamicznych.
Jak Google radzi sobie z renderowaniem JavaScriptu?
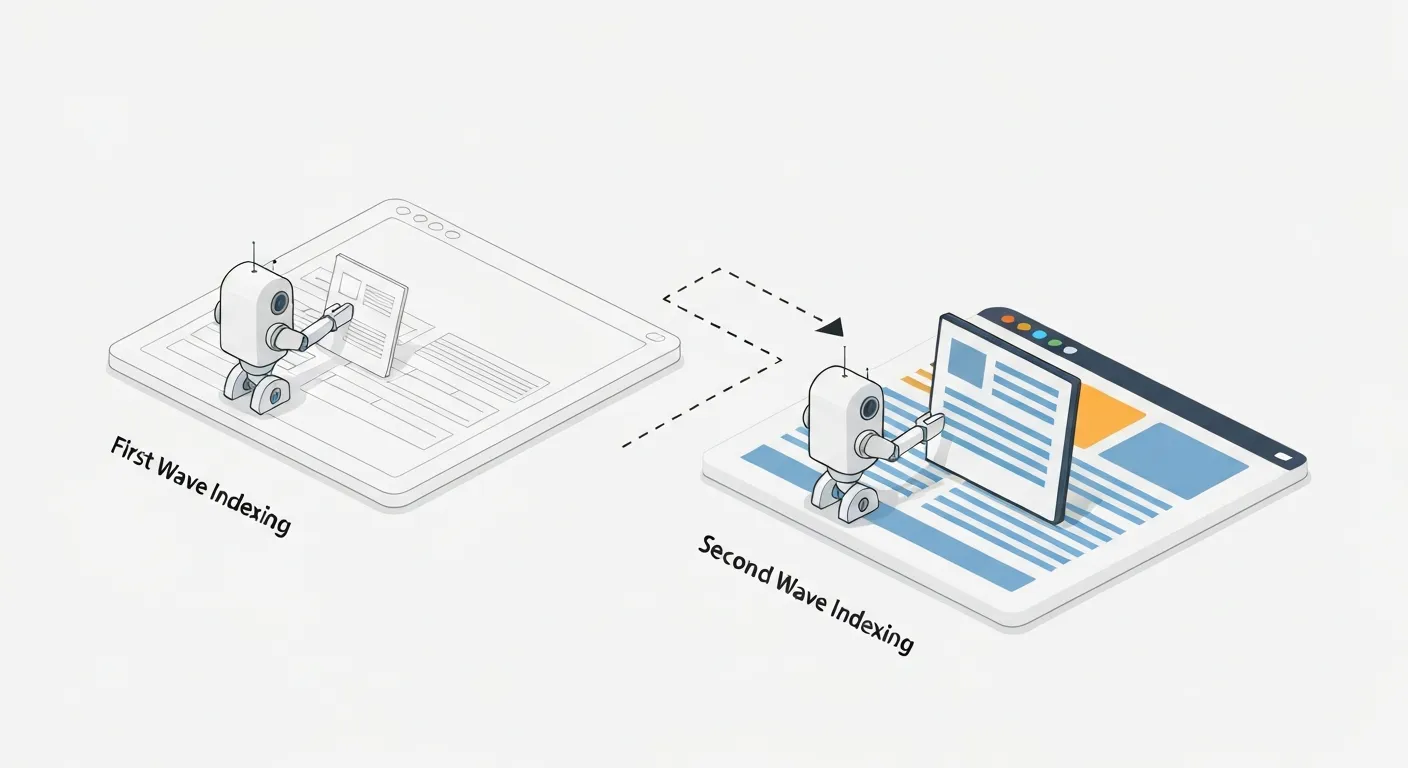
Google zainwestowało ogromne środki w rozwój swojej zdolności do przetwarzania stron opartych na JavaScripcie. Proces ten jest jednak bardziej skomplikowany niż w przypadku statycznych stron i przebiega w dwóch głównych falach. Zrozumienie tego mechanizmu jest kluczowe do diagnozowania problemów.
Proces indeksowania strony dynamicznej wygląda następująco:
- Crawling (Pobieranie): Googlebot wysyła żądanie do serwera i pobiera początkowy kod HTML strony. W przypadku typowej aplikacji SPA, ten kod jest często bardzo ubogi w treść – może zawierać jedynie pusty element
<div id="root"></div>I odwołania do plików JS. - Pierwsza fala indeksowania: Google analizuje pobrany kod HTML. Indeksuje wszystko, co w nim znajdzie – metadane, linki w tagach
<a href="...">, Treść. Jeśli w tym kodzie nie ma nic wartościowego, strona może zostać zindeksowana jako pusta lub o bardzo niskiej jakości. - Kolejka do renderowania: Strona zostaje umieszczona w globalnej kolejce do renderowania. Google musi zarządzać zasobami, więc strony, które wymagają wykonania JavaScriptu, muszą poczekać na swoją kolej. To oczekiwanie może trwać od kilku sekund do nawet kilku dni w skrajnych przypadkach.
- Renderowanie (WRS): Usługa Web Rendering Service (WRS), która jest zasadniczo pełną, aktualną wersją przeglądarki Google Chrome, otwiera stronę. WRS wykonuje kod JavaScript, pobiera dane z zewnętrznych API i generuje finalny, w pełni wyrenderowany kod DOM (Document Object Model). To jest wersja strony, którą widzi użytkownik.
- Druga fala indeksowania: Googlebot ponownie analizuje stronę, ale tym razem korzysta z wyrenderowanego przez WRS kodu DOM. Dopiero teraz odkrywa treść, linki i metadane, które zostały dodane dynamicznie. Na podstawie tych informacji aktualizuje swój indeks.
Kluczowy wniosek: Istnieje tzw. „luka indeksacyjna” (indexing gap) pomiędzy pierwszą a drugą falą. W tym czasie Google może mieć niekompletny lub wręcz błędny obraz Twojej strony. Jeśli ważne zmiany (np. Aktualizacja ceny produktu) są wprowadzane przez JS, mogą one pojawić się w indeksie Google z opóźnieniem. Co gorsza, jeśli proces renderowania z jakiegoś powodu się nie powiedzie, treść może nigdy nie zostać prawidłowo zindeksowana. Dlatego poleganie w 100% na renderowaniu po stronie klienta (Client-Side Rendering) jest ryzykowne z perspektywy SEO.
Najczęstsze problemy SEO związane z JavaScriptem
Problemy z JavaScript SEO Często wynikają z faktu, że deweloperzy skupiają się na doświadczeniu użytkownika, zapominając o perspektywie robota. Oto najczęstsze pułapki, na które należy uważać:
Treść i linki niewidoczne w początkowym HTML
To fundamentalny problem. Jeśli cała treść strony, w tym kluczowe nagłówki, akapity i wezwania do działania, jest ładowana dynamicznie, Googlebot w pierwszej fali indeksowania widzi pustą stronę. To samo dotyczy nawigacji – jeśli menu jest generowane przez JS, robot może nie odkryć linków do innych podstron.
Błędne użycie tagów do nawigacji
Roboty wyszukiwarek są zaprogramowane, aby podążać za linkami umieszczonymi w standardowych tagach <a> Z atrybutem href. Deweloperzy frameworków JS często tworzą nawigację opartą na innych elementach, takich jak <div> Czy <span> Z dołączonym zdarzeniem onClick. Dla użytkownika efekt jest ten sam, ale dla robota taki element nie jest linkiem i nie będzie on za nim podążał. Zawsze należy używać <a href="/sciezka-do-strony"> Dla linków wewnętrznych.
Dynamiczne zarządzanie metadanymi
Każda podstrona w serwisie powinna mieć unikalny tag <title> I <meta name="description">. W aplikacjach SPA, gdzie zmiana „strony” nie powoduje przeładowania, te metadane muszą być aktualizowane dynamicznie przez JavaScript. Jeśli ten proces zawiedzie lub będzie opóźniony, wszystkie podstrony mogą być indeksowane z tymi samymi, domyślnymi metadanymi ze strony głównej, co jest katastrofą dla SEO.
Problemy z wydajnością i Core Web Vitals
Duże, niezoptymalizowane pliki JavaScript mogą drastycznie spowolnić ładowanie strony. Ma to bezpośredni wpływ na wskaźniki Core Web Vitals (LCP, INP, CLS), które są czynnikiem rankingowym Google. Długi czas do interaktywności (TTI) może również zniechęcić zarówno użytkowników, jak i spowodować, że Googlebot zrezygnuje z oczekiwania na pełne wyrenderowanie strony.
Zablokowane zasoby w pliku robots.txt
Aby poprawnie wyrenderować stronę, WRS musi mieć dostęp do wszystkich niezbędnych plików JS, CSS i zasobów API. Czasami, w wyniku błędnej konfiguracji, plik robots.txt Blokuje dostęp do katalogów z tymi plikami. Skutek? Google widzi stronę bez stylów i funkcjonalności, często jako nieczytelny blok tekstu, co uniemożliwia prawidłową ocenę i indeksację.
Brak obsługi unikalnych adresów URL
W aplikacjach SPA nawigacja między widokami odbywa się bez przeładowywania strony. Kluczowe jest, aby każda logiczna podstrona (np. Strona produktu, wpis na blogu) miała swój własny, unikalny adres URL. Do zarządzania tym służy History API. Jeśli cała aplikacja działa pod jednym adresem URL, Google zindeksuje tylko jeden widok – zazwyczaj stronę główną.
Kluczowe rozwiązania: renderowanie po stronie serwera i jego alternatywy

Skoro poleganie na renderowaniu po stronie klienta (CSR – Client-Side Rendering) jest ryzykowne, jakie mamy alternatywy? Na szczęście istnieje kilka sprawdzonych strategii, które pozwalają pogodzić dynamiczny świat JavaScriptu z wymaganiami SEO. Wybór odpowiedniej zależy od specyfiki projektu, budżetu i zasobów technicznych.
1. Renderowanie po stronie serwera (Server-Side Rendering – SSR)
Jak to działa: Kiedy użytkownik lub robot żąda strony, serwer wykonuje kod JavaScript, renderuje pełny, gotowy kod HTML z całą treścią i wysyła go do przeglądarki. Dopiero po załadowaniu tego HTML-a, JavaScript „przejmuje” stronę (proces zwany hydratacją), czyniąc ją w pełni interaktywną.
- Zalety: To złoty standard w JavaScript SEO. Roboty otrzymują w pełni uformowaną stronę od razu, eliminując potrzebę renderowania i lukę indeksacyjną. Jest to również korzystne dla użytkowników, ponieważ znacznie skraca czas do pierwszego wyrenderowania treści (FCP).
- Wady: Wymaga bardziej zaawansowanej konfiguracji serwera (opartego na Node.js) i może generować większe obciążenie, ponieważ każda strona jest renderowana na żywo.
- Technologie: Next.js (dla React), Nuxt.js (dla Vue), Angular Universal.
2. Generowanie stron statycznych (Static Site Generation – SSG)
Jak to działa: Zamiast renderować stronę na żywo, cały serwis jest renderowany do postaci statycznych plików HTML w momencie budowania aplikacji (np. Podczas wdrażania na serwer). Użytkownik otrzymuje gotowy, niezwykle szybki plik statyczny.
- Zalety: Niezrównana wydajność, bezpieczeństwo i prostota hostingu. Perfekcyjne rozwiązanie dla SEO, ponieważ roboty otrzymują gotowe, statyczne strony.
- Wady: Nie nadaje się do treści, które zmieniają się bardzo często lub są personalizowane (np. Profile użytkowników, aktualności na żywo). Każda zmiana wymaga ponownego zbudowania całej strony lub jej części.
- Technologie: Gatsby, Next.js (w trybie SSG), Jekyll, Hugo.
3. Renderowanie dynamiczne (Dynamic Rendering)
Jak to działa: To rozwiązanie hybrydowe, które oficjalnie rekomenduje Google jako obejście problemu dla istniejących aplikacji. Serwer jest skonfigurowany tak, aby wykrywać, kto żąda strony. Jeśli jest to użytkownik, otrzymuje standardową aplikację CSR. Jeśli jest to zidentyfikowany robot (np. Googlebot), serwer kieruje go do specjalnej usługi (np. Puppeteer, Prerender.io), która renderuje stronę i zwraca robotowi statyczną wersję HTML.
- Zalety: Pozwala na „naprawienie” SEO w istniejącej aplikacji CSR bez konieczności przepisywania całej architektury.
- Wady: Wymaga dodatkowej infrastruktury i konfiguracji. Istnieje ryzyko bycia posądzonym o cloaking (maskowanie), jeśli treść serwowana robotom znacząco różni się od tej dla użytkowników. Kluczowe jest, aby obie wersje były jak najbardziej zbliżone.
Praktyczne wskazówki i dobre praktyki w JavaScript SEO
Niezależnie od wybranej strategii renderowania, istnieje szereg dobrych praktyk, o których należy pamiętać, aby zoptymalizować dynamiczną stronę pod kątem wyszukiwarek.
- Używaj narzędzi diagnostycznych: Regularnie korzystaj z Narzędzia do sprawdzania adresów URL w Google Search Console. Funkcja „Testuj bieżący URL” pokaże Ci zrzut ekranu, kod HTML i ewentualne błędy, jakie Google napotkało podczas renderowania Twojej strony. To najlepszy sposób, by zobaczyć witrynę oczami Googlebota.
- Zapewnij czyste i unikalne adresy URL: Każdy unikalny zasób na stronie musi mieć własny, dedykowany adres URL. Unikaj używania fragmentów hasha (
#) Do nawigacji. - Implementuj tagi kanoniczne: Aby uniknąć problemów z duplikacją treści, upewnij się, że każda strona ma poprawnie zaimplementowany, samoodwołujący się tag
rel="canonical". - Zadbaj o dane strukturalne (Schema.org): Umieszczanie danych strukturalnych w formacie JSON-LD w kodzie strony pomaga Google lepiej zrozumieć jej zawartość (np. Że to jest produkt, przepis czy artykuł) i może prowadzić do wyświetlania rozszerzonych wyników w SERP.
- Audytuj plik robots.txt: Upewnij się, że nie blokujesz dostępu do żadnych krytycznych plików .js, .css czy zasobów API.
- Zoptymalizuj wydajność ładowania: Kompresuj pliki JavaScript, stosuj code-splitting (dzielenie kodu na mniejsze części ładowane na żądanie), wykorzystuj leniwe ładowanie (lazy loading) dla obrazów i komponentów poniżej linii zgięcia (above the fold).
- Stosuj poprawne kody statusu HTTP: Aplikacja SPA musi poprawnie obsługiwać błędy. Strona, która nie istnieje, powinna zwracać kod 404, a nie „miękki 404” (czyli stronę z komunikatem o błędzie, ale z kodem statusu 200 OK).
Zakończenie: Partnerstwo SEO i deweloperów kluczem do sukcesu
JavaScript SEO Nie jest już niszową specjalizacją, ale fundamentalnym elementem nowoczesnej optymalizacji stron. Dynamiczne, interaktywne witryny to przyszłość internetu, a ignorowanie ich specyficznych wymagań z perspektywy wyszukiwarek to prosta droga do cyfrowej niewidzialności. Kluczem do sukcesu jest świadomość, że poleganie wyłącznie na zdolnościach Google do renderowania JavaScriptu jest strategią ryzykowną i nieoptymalną.
Najskuteczniejsze podejście, takie jak renderowanie po stronie serwera (SSR) czy generowanie stron statycznych (SSG), polega na ułatwieniu pracy robotom poprzez serwowanie im gotowej, w pełni uformowanej treści. To nie tylko rozwiązuje problemy z indeksacją, ale również pozytywnie wpływa na doświadczenia użytkowników dzięki szybszemu ładowaniu stron. Ostateczny sukces w dziedzinie JavaScript SEO Zależy od ścisłej współpracy między specjalistami SEO a zespołami deweloperskimi. SEO musi stać się integralną częścią procesu tworzenia aplikacji od samego początku, a nie dodatkiem na sam koniec. Tylko dzięki takiemu partnerstwu możemy budować zaawansowane, nowoczesne serwisy, które są nie tylko zachwycające dla użytkowników, ale także w pełni widoczne i doceniane przez wyszukiwarki.
Zobacz więcej:
- Link bait: Czym jest i jak go skutecznie tworzyć, by zdobywać wartościowe linki?
- Optymalizator konwersji: wszystko, co musisz wiedzieć o narzędziu Google Ads
- Exit rate: co to jest i jak go analizować?
- Co to są zindeksowane strony i jak sprawdzić ich status w Google?
- X (dawniej Twitter): co to jest, jak działa i czy warto go używać w 2024 roku?
Dodaj komentarz