

W dzisiejszym cyfrowym ekosystemie dane są walutą. Każda interakcja użytkownika z Twoją stroną internetową – od kliknięcia w przycisk, przez obejrzenie wideo, aż po finalizację zakupu – generuje cenne informacje. Prawdziwe wyzwanie nie polega jednak na samym gromadzeniu danych, ale na ich jakości, spójności i dostępności. To właśnie tutaj na scenę wkracza cichy bohater nowoczesnej analityki internetowej: data layer. Dla wielu marketerów termin ten brzmi technicznie i onieśmielająco, ale jego zrozumienie jest absolutnie kluczowe do podejmowania trafnych decyzji biznesowych i pełnego wykorzystania potencjału narzędzi analitycznych. To nie jest tylko kolejny techniczny żargon; to fundament, na którym buduje się całą strategię pomiaru i optymalizacji.
Wyobraź sobie, że próbujesz zbudować solidny dom na niestabilnym gruncie. Nieważne, jak wspaniałe będą Twoje plany i jak drogie materiały – cała konstrukcja będzie zagrożona. W świecie analityki, Twoje narzędzia (Google Analytics, Facebook Pixel, Hotjar) to właśnie ten dom, a data layer To solidny, starannie przygotowany fundament. Bez niego Twoje raporty mogą być niedokładne, dane niespójne, a wdrażanie nowych narzędzi śledzących staje się koszmarem. W tym artykule przeprowadzimy Cię przez świat warstwy danych, wyjaśniając prostym językiem, czym jest, dlaczego jest niezbędna i jak rewolucjonizuje sposób, w jaki firmy podchodzą do analizy danych online.
Co to jest data layer? Definicja dla nie-technicznych
W najprostszym ujęciu, data layer (Warstwa danych) to niewidzialna dla użytkownika struktura na Twojej stronie internetowej, która działa jak zorganizowany pośrednik. To wirtualny kontener, w którym strona internetowa umieszcza wszystkie ważne informacje o tym, co się na niej dzieje, w ustandaryzowany i uporządkowany sposób. Zamiast pozwalać narzędziom analitycznym (takim jak Google Tag Manager) na „zgadywanie” lub „szukanie” informacji po całej stronie, data layer Serwuje im je na tacy, w czystej i gotowej do użycia formie.
Technicznie rzecz biorąc, jest to obiekt JavaScript, który przechowuje kluczowe dane w formie par klucz-wartość. Pomyśl o tym jak o cyfrowej „karcie informacyjnej” dla każdej strony i każdej interakcji. Karta ta może zawierać informacje takie jak:
- Informacje o stronie: Nazwa strony, kategoria (np. „blog”, „produkt”, „kontakt”), język.
- Informacje o użytkowniku: Status zalogowania (np. „zalogowany”, „gość”), ID klienta, typ klienta (np. „nowy”, „powracający”).
- Informacje o produkcie (w e-commerce): Nazwa produktu, ID, cena, kategoria, marka.
- Informacje o transakcji: ID zamówienia, wartość całkowita, koszty wysyłki, użyty kod rabatowy.
Gdy użytkownik wykonuje na stronie jakąś akcję, np. Dodaje produkt do koszyka, strona nie tylko wizualnie aktualizuje koszyk. W tle, deweloperzy programują ją tak, aby „wypchnęła” (ang. Push) informację o tym zdarzeniu do data layer. Wygląda to mniej więcej tak (w uproszczeniu):
dataLayer.push({
'event': 'addToCart',
'ecommerce': {
'currencyCode': 'PLN',
'add': {
'products': [{
'name': 'Eleganckie Buty Skórzane',
'id': 'EBS-43-CZ',
'price': '349.99',
'brand': 'Marka Premium',
'category': 'Obuwie Męskie/Eleganckie',
'quantity': 1
}]
}
}
});
Ta struktura jest następnie odczytywana przez menedżery tagów, takie jak Google Tag Manager (GTM). GTM „nasłuchuje” na takie zdarzenia jak 'addToCart’ i gdy je wykryje, może uruchomić odpowiednie tagi – wysłać informację do Google Analytics, Facebooka, Google Ads i każdego innego narzędzia, które skonfigurujesz. Dzięki temu wszystkie Twoje narzędzia marketingowe otrzymują tę samą, spójną i kompletną informację o zdarzeniu.
Dlaczego standardowe śledzenie to za mało?
Wielu marketerów zaczyna swoją przygodę z analityką od prostego wklejenia kodu śledzącego Google Analytics bezpośrednio na stronę. Na początku to wystarcza do mierzenia odsłon czy podstawowych celów. Jednak w miarę jak biznes rośnie, a potrzeby analityczne stają się bardziej zaawansowane, ten model szybko pokazuje swoje ograniczenia. Poleganie na standardowym śledzeniu lub konfigurowaniu zdarzeń w GTM w oparciu o elementy strony (tzw. „DOM scraping”) jest podejściem kruchym i nieefektywnym. Oto dlaczego:
- Brak stabilności i kruchość danych: Wyobraź sobie, że skonfigurowałeś w GTM regułę, która śledzi kliknięcia w przycisk „Dodaj do koszyka” na podstawie jego klasy CSS, np. „btn-add-to-cart-main”. Wszystko działa świetnie, dopóki deweloper lub projektant nie zdecyduje się na redesign strony i nie zmieni tej klasy na „button-primary-purchase”. Twoje śledzenie natychmiast przestaje działać, a Ty tracisz dane, często nie zdając sobie z tego sprawy przez wiele dni. Data layer Uniezależnia śledzenie od wyglądu strony. Zdarzenie 'addToCart’ jest wysyłane niezależnie od tego, jak wygląda i jak nazywa się przycisk.
- Niespójność i bałagan w nazewnictwie: Bez centralnego standardu, różne działy lub nawet różne narzędzia mogą śledzić to samo zdarzenie pod innymi nazwami. Marketing może nazwać zapis na newsletter „newsletter_signup”, podczas gdy analityka śledzi go jako „form_submission_newsletter”. Prowadzi to do chaosu w raportach i uniemożliwia porównywanie danych między systemami. Data layer Wymusza stworzenie jednej, spójnej „mapy danych” dla całej organizacji.
- Ograniczony dostęp do informacji: Standardowe śledzenie widzi tylko to, co jest widoczne na stronie. Co jednak z informacjami, które są kluczowe dla biznesu, ale nie są bezpośrednio widoczne w warstwie wizualnej? Przykłady to marża na produkcie, status lojalnościowy klienta, koszt pozyskania leada czy informacja, czy produkt jest aktualnie w promocji. Tych danych nie da się „wyklikać” w GTM. Data layer Pozwala deweloperom na przekazanie tych bezcennych, kontekstowych informacji prosto z backendu systemu, otwierając drzwi do znacznie głębszej analizy.
- Problemy ze skalowalnością i zarządzaniem: Wraz z dodawaniem kolejnych narzędzi marketingowych (piksele afiliacyjne, narzędzia do remarketingu, platformy marketing automation), każde z nich wymaga własnej konfiguracji śledzenia. Bez data layer, Proces ten staje się powolny, kosztowny i podatny na błędy. Z warstwą danych, wszystkie narzędzia czerpią z tego samego, jednego źródła prawdy. Dodanie nowego narzędzia sprowadza się do skonfigurowania go w GTM, aby „słuchało” odpowiednich zdarzeń z data layer, Co jest znacznie szybsze i bezpieczniejsze.
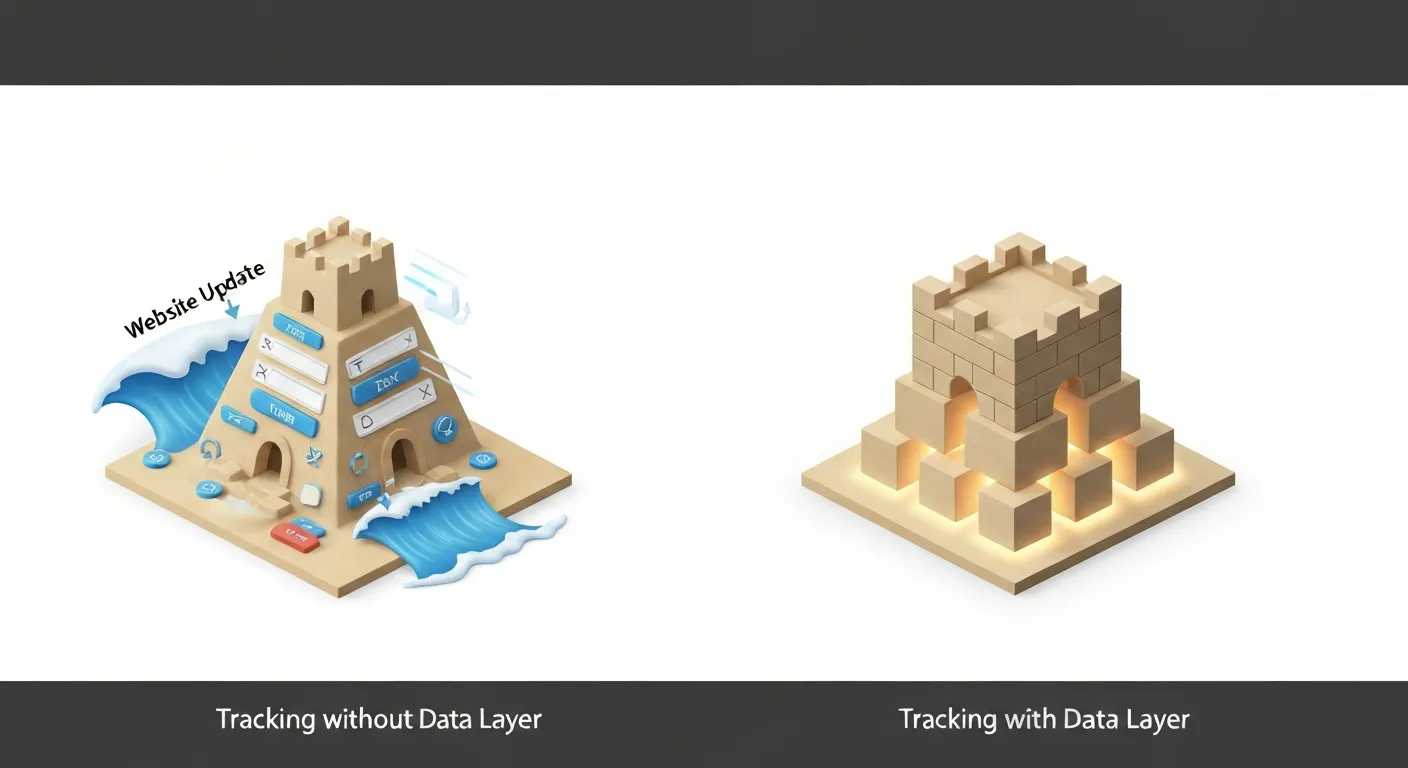
Krótko mówiąc, poleganie na śledzeniu opartym o strukturę strony jest jak budowanie zamku z piasku. Może wyglądać dobrze przez chwilę, ale pierwsza fala (zmiana w kodzie strony) może zniszczyć całą Twoją pracę. Data layer To solidna, skalowalna architektura, która przetrwa próbę czasu.
Kluczowe korzyści z wdrożenia data layer
Inwestycja czasu i zasobów w prawidłowe wdrożenie data layer Przynosi wymierne korzyści, które wykraczają daleko poza samo uporządkowanie danych. To strategiczna decyzja, która wpływa na efektywność marketingu, jakość analiz i szybkość działania całej organizacji w cyfrowym świecie.
1. Standaryzacja i wiarygodność danych
To fundamentalna korzyść. Data layer Staje się jedynym, oficjalnym źródłem prawdy (Single Source of Truth) o interakcjach użytkowników. Wprowadza jednolity słownik pojęć dla całej firmy. Niezależnie od tego, czy patrzysz na raport w Google Analytics, Facebook Ads czy wewnętrznym systemie BI, „zakup” zawsze oznacza to samo i zawiera ten sam zestaw atrybutów. Taka spójność eliminuje nieporozumienia i buduje zaufanie do danych, co jest fundamentem kultury data-driven.
2. Niezależność marketingu od działu IT
Po wdrożeniu data layer, Rola działu IT w codziennym zarządzaniu analityką znacznie maleje. Marketingowcy, korzystając z interfejsu Google Tag Manager, mogą samodzielnie wdrażać nowe tagi, modyfikować istniejące i prowadzić testy, bez konieczności proszenia deweloperów o dodawanie kolejnych fragmentów kodu na stronę przy każdej kampanii. GTM staje się potężnym narzędziem w rękach marketingu, a deweloperzy mogą skupić się na rozwijaniu produktu. Współpraca jest nadal kluczowa na etapie planowania, ale codzienna praca staje się znacznie bardziej autonomiczna.
3. Wzbogacone dane i głębsze insighty
Jak wspomniano wcześniej, data layer Pozwala na przekazywanie danych, które nie są widoczne na stronie. Możliwości są tu niemal nieograniczone. Możesz przekazywać:
- Atrybuty użytkownika: Customer Lifetime Value (CLV), status w programie lojalnościowym, data ostatniego zakupu.
- Atrybuty produktu: Marża, dostępność w magazynie, koszt produkcji, dostawca.
- Kontekst sesji: Czy użytkownik korzysta z wyszukiwarki wewnętrznej, jakie filtry zastosował, czy widział konkretny baner promocyjny.
Posiadanie takich danych w Google Analytics pozwala na tworzenie niezwykle zaawansowanych segmentów i raportów, odpowiadając na pytania takie jak: „Jaki jest zwrot z inwestycji w kampanie dla klientów o wysokim CLV?” albo „Które kategorie produktów o wysokiej marży są najczęściej oglądane, ale rzadko kupowane?”.
4. Lepsza wydajność i bezpieczeństwo strony
Zamiast wielu różnych skryptów śledzących odpalanych w różnych momentach i w różny sposób, data layer W połączeniu z GTM centralizuje zarządzanie tagami. Pozwala to na asynchroniczne ładowanie skryptów, co może pozytywnie wpłynąć na szybkość ładowania strony (Page Speed), kluczowy czynnik zarówno dla SEO, jak i doświadczenia użytkownika. Dodatkowo, masz pełną kontrolę nad tym, jakie dane są wysyłane do zewnętrznych dostawców, co jest niezwykle ważne w kontekście RODO (GDPR) i ogólnego bezpieczeństwa danych.
Jak wygląda struktura data layer w praktyce?
Struktura data layer Powinna być logiczna, przemyślana i dobrze udokumentowana. Chociaż nie ma jednego, uniwersalnego standardu, istnieją dobre praktyki, które warto naśladować, takie jak te promowane przez Google dla modułu Enhanced Ecommerce. Zazwyczaj struktura opiera się na dwóch głównych elementach: zmiennych i zdarzeniach.
Zmienne (Variables)
Są to informacje, które opisują ogólny kontekst strony lub użytkownika i są zazwyczaj dostępne od razu po załadowaniu strony. Umieszcza się je w obiekcie data layer Na początku kodu strony. Przykładowa struktura zmiennych może wyglądać tak:
dataLayer = [{
'pageCategory': 'Blog',
'pagePostAuthor': 'Jan Kowalski',
'visitorType': 'Returning Visitor',
'loginStatus': 'logged-in'
}];
Dzięki temu, dla każdej odsłony, Google Tag Manager może odczytać te wartości i przekazać je jako niestandardowe wymiary do Google Analytics, co pozwala na segmentację ruchu np. Według typu użytkownika czy kategorii przeglądanych treści.
Zdarzenia (Events)
Są to informacje o konkretnych akcjach, które użytkownik wykonuje na stronie. Są one „wypychane” do data layer W momencie wykonania akcji za pomocą funkcji dataLayer.push(). Każde zdarzenie powinno mieć unikalną nazwę (klucz 'event’) oraz opcjonalnie dodatkowe parametry opisujące to zdarzenie.
Przykład 1: Wysłanie formularza kontaktowego
dataLayer.push({
'event': 'formSubmission',
'formName': 'Kontakt Główny',
'formLocation': 'footer'
});
Przykład 2: Pełne zdarzenie transakcji w e-commerce
dataLayer.push({
'event': 'purchase',
'ecommerce': {
'transaction_id': 'T12345',
'affiliation': 'Sklep Internetowy',
'value': 250.75,
'tax': 46.90,
'shipping': 15.00,
'currency': 'PLN',
'coupon': 'LATO2024',
'items': [
{
'item_name': 'Koszulka Bawełniana',
'item_id': 'KB-M-NIEB',
'price': 79.99,
'item_brand': 'Fajna Marka',
'item_category': 'Odzież',
'quantity': 2
},
{
'item_name': 'Czapka z Daszkiem',
'item_id': 'CZD-UNI-CZAR',
'price': 59.99,
'item_brand': 'Inna Marka',
'item_category': 'Akcesoria',
'quantity': 1
}
]
}
});
Kluczowe jest stworzenie spójnej konwencji nazewnictwa (np. CamelCase: `formName` lub snake_case: `form_name`) i trzymanie się jej w całym projekcie.
Proces wdrożenia data layer krok po kroku
Wdrożenie data layer To projekt, który wymaga ścisłej współpracy między marketingiem, analitykami i deweloperami. Nie jest to coś, co można zrobić „na szybko”. Prawidłowy proces powinien obejmować następujące etapy:
- Definicja wymagań biznesowych. Wszystko zaczyna się od strategii. Zanim napiszesz linijkę kodu, musisz odpowiedzieć na pytania: Co chcemy mierzyć? Jakie są nasze kluczowe wskaźniki efektywności (KPI)? Jakie decyzje chcemy podejmować na podstawie danych? Na tym etapie tworzy się tzw. „plan pomiaru” (measurement plan).
- Stworzenie specyfikacji technicznej. Plan pomiaru jest następnie tłumaczony na język techniczny. Analityk lub specjalista od wdrożeń tworzy szczegółowy dokument, który opisuje, jakie zmienne i zdarzenia mają znaleźć się w data layer, Jakie mają mieć nazwy i jakie wartości przyjmować. To jest instrukcja dla deweloperów.
- Implementacja przez dział IT. Deweloperzy, na podstawie specyfikacji, implementują kod data layer Na stronie internetowej lub w aplikacji. To oni są odpowiedzialni za poprawne przekazywanie danych z backendu i frontend u do warstwy danych w odpowiednich momentach.
- Testowanie i walidacja. To absolutnie krytyczny etap. Po implementacji, analityk musi dokładnie sprawdzić, czy wszystkie dane pojawiają się w data layer Poprawnie. Używa się do tego narzędzi deweloperskich w przeglądarce, trybu podglądu w GTM oraz specjalnych wtyczek (np. DataSlayer, Adswerve dataLayer Inspector+). Każdy scenariusz użytkownika musi być przetestowany.
- Konfiguracja w Google Tag Manager. Gdy data layer Działa poprawnie, można przystąpić do jego wykorzystania. W GTM tworzy się „Zmienne warstwy danych” (Data Layer Variables), które odczytują wartości z data layer, Oraz „Reguły” (Triggers) oparte na zdarzeniach niestandardowych. Dopiero wtedy buduje się tagi, które wysyłają te uporządkowane dane do docelowych narzędzi.
Najczęstsze błędy przy implementacji data layer
Wdrożenie data layer Może pójść nie tak na wiele sposobów. Znajomość najczęstszych pułapek pomoże Ci ich uniknąć.
- Brak planu i dokumentacji: To grzech pierworodny. Wdrażanie data layer Bez solidnego planu pomiaru i specyfikacji technicznej to prosta droga do chaosu, niespójnych danych i konieczności poprawek w przyszłości.
- Zbyt skomplikowana struktura: Czasami w dobrej wierze tworzy się nadmiernie rozbudowaną warstwę danych, próbując śledzić wszystko, co tylko możliwe. Prowadzi to do trudności w implementacji i utrzymaniu. Zacznij od tego, co jest absolutnie kluczowe dla biznesu i rozbudowuj strukturę w miarę potrzeb.
- Niespójne nazewnictwo: Używanie `productID` na jednej stronie i `productId` na innej to częsty błąd. Stwórz i egzekwuj jedną konwencję nazewnictwa w całej dokumentacji.
- Brak współpracy między marketingiem a IT: Data layer To projekt interdyscyplinarny. Marketing musi jasno określić, „co” i „dlaczego” chce mierzyć, a IT musi poprawnie zaimplementować „jak”. Brak komunikacji i wzajemnego zrozumienia na tej linii jest gwarancją porażki.
- Pominięcie etapu testowania: Ufanie, że „na pewno działa” to prosta droga do zbierania błędnych danych. Każdy element data layer Musi być rygorystycznie przetestowany przed wdrożeniem tagów na produkcję.
Zakończenie: Inwestycja w przyszłość Twoich danych
Data layer To znacznie więcej niż tylko techniczny detal. To fundamentalna zmiana w podejściu do analityki internetowej – przejście od reaktywnego i chaotycznego zbierania danych do proaktywnej, ustrukturyzowanej i strategicznej architektury pomiaru. To inwestycja, która zwraca się wielokrotnie w postaci wiarygodnych raportów, głębszych analiz, szybszego wdrażania narzędzi marketingowych i, co najważniejsze, lepszych decyzji biznesowych.
W erze, gdzie personalizacja, automatyzacja i ochrona prywatności (w tym nadchodzący świat bez plików cookie stron trzecich) stają się kluczowe, posiadanie własnego, dobrze zorganizowanego źródła danych o interakcjach użytkowników jest nieocenioną przewagą konkurencyjną. Traktuj data layer Nie jako koszt, ale jako strategiczny zasób. To solidny fundament, na którym możesz bezpiecznie budować i rozwijać analityczną dojrzałość swojej organizacji przez wiele lat.
Zobacz więcej:
- Wizualizacja lejka sprzedażowego: czym jest i jak ją stworzyć?
- Przekierowanie 302: Zastosowanie tymczasowego redirectu w SEO
- Kampania re-engagementowa: Kompletny przewodnik, jak odzyskać nieaktywnych klientów
- Optymalizator konwersji: wszystko, co musisz wiedzieć o narzędziu Google Ads
- User Explorer w GA4: jak krok po kroku analizować ścieżki pojedynczych użytkowników?
Dodaj komentarz