

Data mining: na czym polega proces odkrywania wiedzy z danych?
Żyjemy w epoce informacyjnej, gdzie dane stały się jednym z najcenniejszych zasobów. Każdego dnia generujemy niewyobrażalne ich ilości – od kliknięć na stronach internetowych, przez transakcje kartą kredytową, aż po dane z czujników IoT. Jednak surowe dane, same w sobie, są jak nieoszlifowany diament – posiadają ogromny potencjał, ale bez odpowiedniej obróbki pozostają bezużyteczne. Tutaj właśnie na scenę wkracza data mining, Czyli proces eksploracji i analizy danych, którego celem jest odkrywanie ukrytych, dotąd nieznanych, ale potencjalnie wartościowych wzorców, relacji i trendów. To nie jest zwykłe raportowanie czy prosta analiza statystyczna. Data mining to cyfrowa archeologia, która pozwala firmom i organizacjom przekształcać chaos informacyjny w strategiczną wiedzę, napędzającą innowacje i dającą przewagę konkurencyjną.
Wyobraźmy sobie ogromny magazyn pełen chaotycznie rozrzuconych przedmiotów. Zwykła kwerenda bazodanowa to jak pytanie pracownika: „ile mamy czerwonych krzeseł?”. Otrzymamy konkretną, liczbową odpowiedź. Natomiast data mining To proces, w którym specjalista, nie mając z góry założonej tezy, wchodzi do tego magazynu i odkrywa, że „osoby, które kupują czerwone krzesła, niemal zawsze dokupują do nich niebieskie poduszki i robią to w środy po południu”. To właśnie tego typu głębokie, nieliniowe i często nieintuicyjne powiązania stanowią istotę odkrywania wiedzy z danych. W tym artykule przyjrzymy się z bliska, na czym polega ten fascynujący proces, jakie techniki wykorzystuje i gdzie znajduje praktyczne zastosowanie.
Czym dokładnie jest data mining i dlaczego to nie to samo co analityka?

Choć terminy „data mining”, „analiza danych” i „Business Intelligence” są często używane zamiennie, reprezentują one różne poziomy pracy z danymi. Zrozumienie tych różnic jest kluczowe, aby w pełni docenić unikalną wartość, jaką oferuje eksploracja danych.
Analiza danych (Data Analysis) I Business Intelligence (BI) Zazwyczaj koncentrują się na przeszłości. Odpowiadają na pytania „co się stało?” i „dlaczego tak się stało?”. Systemy BI wykorzystują dane historyczne do tworzenia raportów, dashboardów i wizualizacji, które pozwalają menedżerom monitorować kluczowe wskaźniki wydajności (KPI). Jest to niezwykle ważne dla bieżącego zarządzania firmą, ale ma charakter głównie opisowy (deskryptywny) i diagnostyczny.
Z kolei data mining Idzie o krok dalej. Jego celem jest nie tylko opisanie przeszłości, ale przede wszystkim przewidywanie przyszłości (analiza predyktywna) i sugerowanie optymalnych działań (analiza preskryptywna). Proces ten nie zaczyna się od konkretnego pytania, ale od hipotezy, że w zbiorze danych ukryte są wartościowe wzorce. Wykorzystuje zaawansowane techniki ze skrzyżowania statystyki, uczenia maszynowego i sztucznej inteligencji, aby automatycznie przeszukiwać ogromne zbiory danych w poszukiwaniu tych wzorców. Można powiedzieć, że BI patrzy we wsteczne lusterko samochodu, podczas gdy data mining próbuje przewidzieć, co wydarzy się za następnym zakrętem, i sugeruje, z jaką prędkością go pokonać.
Fundamentalnym założeniem data mining jest to, że historyczne dane zawierają informacje, które mogą być użyte do modelowania przyszłych zachowań. Proces ten jest z natury interdyscyplinarny i wymaga nie tylko umiejętności technicznych, ale również głębokiego zrozumienia domeny biznesowej, w której jest stosowany.
Kluczowe etapy procesu data mining w modelu CRISP-DM
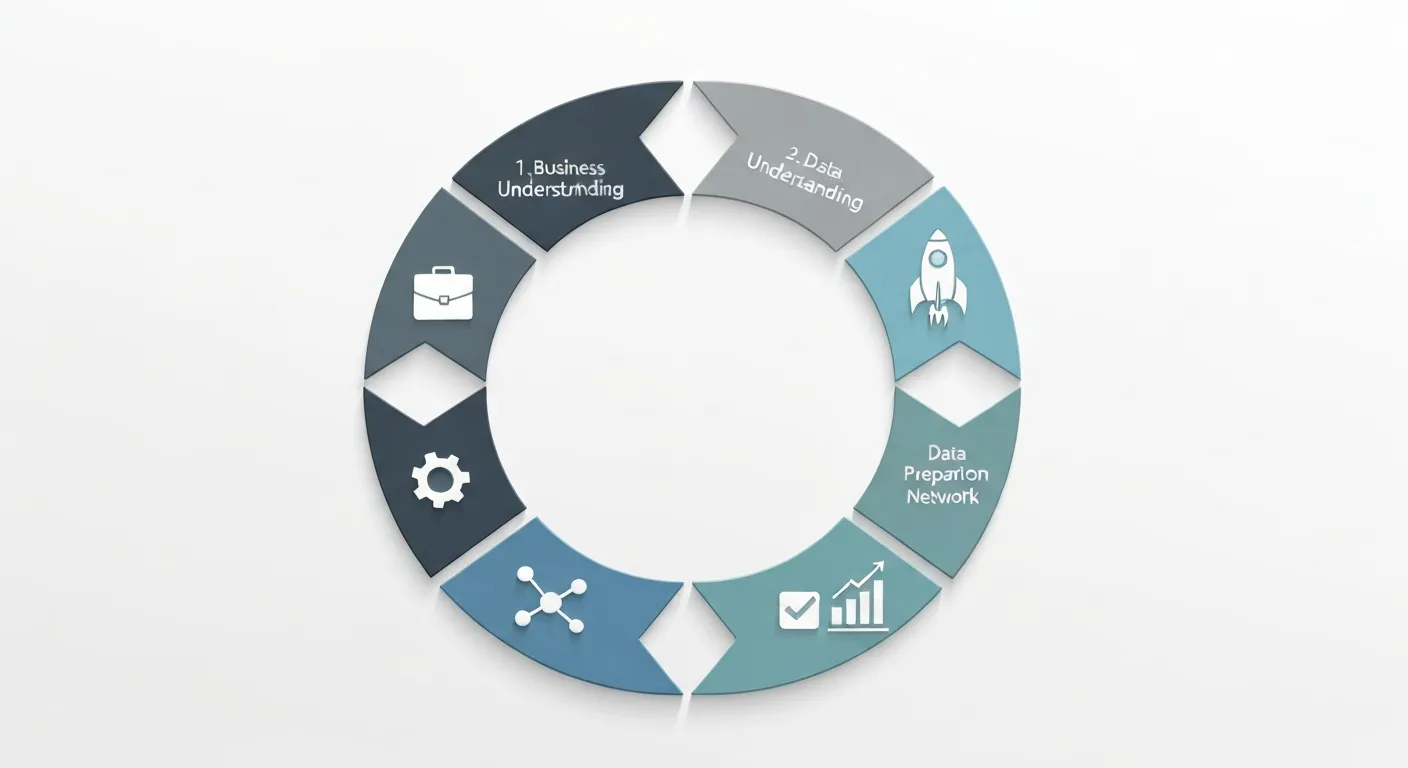
Proces data mining nie jest chaotycznym „grzebaniem w danych”. To ustrukturyzowana metodologia, która zapewnia powtarzalność i skuteczność projektów. Najpopularniejszym i najszerzej stosowanym standardem w branży jest CRISP-DM (Cross-Industry Standard Process for Data Mining). Model ten dzieli cały proces na sześć logicznych, następujących po sobie faz, które często wymagają powrotu do wcześniejszych etapów w iteracyjnym cyklu.
-
Zrozumienie biznesowe (Business Understanding)
To absolutnie fundamentalny i najważniejszy etap. Zanim napiszemy choćby jedną linijkę kodu, musimy precyzyjnie zrozumieć, jaki problem biznesowy chcemy rozwiązać. Czy celem jest zmniejszenie liczby klientów odchodzących do konkurencji (tzw. Churn)? A może optymalizacja kampanii marketingowej? Zwiększenie sprzedaży krzyżowej? Na tym etapie definiujemy cele projektu, określamy kryteria sukcesu (np. „zmniejszenie churnu o 15% w ciągu 6 miesięcy”) i przekładamy problem biznesowy na konkretne zadanie data mining (np. „zbudowanie modelu klasyfikacyjnego przewidującego, którzy klienci są najbardziej narażeni na odejście”). -
Zrozumienie danych (Data Understanding)
Gdy wiemy, czego szukamy, musimy sprawdzić, jakimi „narzędziami” dysponujemy. Ten etap polega na zebraniu wstępnych danych i zapoznaniu się z nimi. Analizujemy, jakie mamy tabele, jakie zawierają kolumny, jakie są typy danych. Przeprowadzamy wstępną eksplorację, wizualizujemy dane, szukamy pierwszych, oczywistych korelacji. Kluczowym elementem jest tutaj ocena jakości danych – czy są kompletne? Czy zawierają błędy lub wartości odstające? To etap, na którym tworzymy pierwsze hipotezy na temat danych. -
Przygotowanie danych (Data Preparation)
Często nazywany „brudną robotą”, ten etap jest najbardziej czasochłonny i może stanowić nawet 80% całego projektu. Surowe dane niemal nigdy nie nadają się bezpośrednio do modelowania. Trzeba je „posprzątać” i przekształcić. Typowe zadania na tym etapie to:- Czyszczenie danych: Uzupełnianie brakujących wartości, usuwanie duplikatów, korygowanie błędów.
- Integracja danych: Łączenie danych z różnych źródeł (np. System CRM, dane transakcyjne, dane z analityki webowej).
- Transformacja danych: Normalizacja, skalowanie wartości numerycznych, zmiana formatu (np. Daty).
- Tworzenie nowych cech (Feature Engineering): Tworzenie nowych, bardziej informacyjnych zmiennych na podstawie istniejących (np. Wiek klienta na podstawie daty urodzenia, średnia wartość transakcji).
Jakość przygotowania danych ma bezpośredni i ogromny wpływ na jakość końcowego modelu. Zasada „śmieci na wejściu, śmieci na wyjściu” (Garbage In, Garbage Out) jest tutaj świętością.
-
Modelowanie (Modeling)
To serce procesu data mining. Na tym etapie wybieramy i aplikujemy odpowiednie techniki oraz algorytmy w celu znalezienia wzorców. W zależności od zdefiniowanego problemu biznesowego, może to być np. Budowa drzewa decyzyjnego do klasyfikacji klientów, zastosowanie regresji liniowej do prognozowania sprzedaży, czy użycie algorytmów klastrowania do segmentacji rynku. Zazwyczaj testuje się kilka różnych modeli i algorytmów, dostrajając ich parametry (tzw. Hiperparametry), aby znaleźć ten, który daje najlepsze wyniki dla naszego konkretnego problemu i zestawu danych. -
Ewaluacja (Evaluation)
Zbudowanie modelu to nie koniec pracy. Teraz musimy ocenić, czy jest on dobry i czy faktycznie rozwiązuje problem biznesowy postawiony na pierwszym etapie. Na tym etapie sprawdzamy techniczne metryki modelu (np. Dokładność, precyzję), ale co ważniejsze – konfrontujemy wyniki z celami biznesowymi. Czy model jest wystarczająco precyzyjny, aby można było na jego podstawie podejmować decyzje? Czy odkryte wzorce są zrozumiałe dla interesariuszy biznesowych? Czy model nie jest obarczony uprzedzeniami (bias)? Jeśli wyniki są niezadowalające, często trzeba wrócić do poprzednich etapów – np. Przygotować dane w inny sposób lub wybrać inną technikę modelowania. -
Wdrożenie (Deployment)
Ostatnim krokiem jest wdrożenie modelu do środowiska produkcyjnego, tak aby mógł on przynosić realną wartość. Wdrożenie może przybierać różne formy – od prostego raportu z listą klientów najbardziej zagrożonych odejściem, po zintegrowanie modelu z systemem e-commerce, który w czasie rzeczywistym będzie personalizował rekomendacje produktowe. Kluczowe jest również zaplanowanie procesu monitorowania modelu – jego wydajność może z czasem spadać w miarę zmiany zachowań klientów, dlatego wymaga on regularnych aktualizacji.
Najważniejsze techniki i algorytmy data mining
Data mining to szeroka dziedzina, która dysponuje bogatym zestawem narzędzi. Wybór odpowiedniej techniki zależy od celu, jaki chcemy osiągnąć. Oto najczęściej stosowane zadania i powiązane z nimi techniki:
Klasyfikacja
Cel: Przypisanie obiektu do jednej z predefiniowanych kategorii. To jedno z najczęstszych zadań. Model uczy się na podstawie historycznych danych, gdzie kategoria każdego obiektu jest znana (uczenie nadzorowane).
Przykłady biznesowe:
- Określanie, czy klient zrezygnuje z usług (kategorie: „odejdzie”, „zostanie”).
- Filtrowanie spamu w skrzynce e-mail (kategorie: „spam”, „nie-spam”).
- Ocena wniosku kredytowego (kategorie: „przyznać kredyt”, „odrzucić”).
Popularne algorytmy: Drzewa decyzyjne, Lasy losowe, Naiwny klasyfikator Bayesa, Maszyny wektorów nośnych (SVM), Sieci neuronowe.
Regresja
Cel: Przewidywanie wartości ciągłej (liczbowej), a nie kategorii. Podobnie jak klasyfikacja, jest to technika uczenia nadzorowanego.
Przykłady biznesowe:
- Prognozowanie ceny domu na podstawie jego cech (powierzchnia, lokalizacja).
- Szacowanie przyszłej sprzedaży produktu.
- Przewidywanie, ile klient wyda w sklepie podczas następnej wizyty.
Popularne algorytmy: Regresja liniowa, Regresja logistyczna, Drzewa regresyjne.
Klastrowanie (Segmentacja)
Cel: Grupowanie podobnych do siebie obiektów w klastry (grupy) bez wcześniejszej wiedzy o tych grupach (uczenie nienadzorowane). Algorytm sam znajduje naturalne podziały w danych.
Przykłady biznesowe:
- Segmentacja klientów na podstawie ich zachowań zakupowych w celu tworzenia spersonalizowanych kampanii.
- Grupowanie dokumentów o podobnej tematyce.
- Identyfikacja różnych typów zachowań użytkowników na stronie internetowej.
Popularne algorytmy: K-średnich (K-Means), Klastrowanie hierarchiczne, DBSCAN.
Analiza asocjacji (Reguły asocjacyjne)
Cel: Odkrywanie reguł opisujących zależności i współwystępowanie różnych elementów w zbiorze danych. To właśnie ta technika stoi za słynnym mitem o „piwie i pieluchach”.
Przykłady biznesowe:
- Analiza koszyka zakupowego: „Jeśli klient kupił produkt A, to z 70% prawdopodobieństwem kupi również produkt B”.
- Rekomendacje produktów w sklepach e-commerce („Klienci, którzy kupili ten produkt, kupili również…”).
- Planowanie układu produktów na półkach w supermarkecie.
Popularne algorytmy: Apriori, Eclat, FP-Growth.
Wykrywanie anomalii
Cel: Identyfikacja obserwacji, które znacząco odbiegają od reszty danych. Są to tzw. Wartości odstające (outliers).
Przykłady biznesowe:
- Wykrywanie oszustw na kartach kredytowych (nietypowe transakcje).
- Monitorowanie awarii w maszynach produkcyjnych (nietypowe odczyty z czujników).
- Wykrywanie włamań do sieci komputerowej.
Praktyczne zastosowania data mining w biznesie
Teoria i techniki data mining przekładają się na konkretne korzyści w niemal każdej branży. Organizacje, które skutecznie wykorzystują eksplorację danych, zyskują potężną przewagę konkurencyjną.
- Marketing i sprzedaż: To dziedzina, w której data mining Zrewolucjonizował podejście do klienta. Umożliwia precyzyjną segmentację, personalizację ofert, tworzenie systemów rekomendacyjnych (jak w Netflix czy Amazon), optymalizację cen i prognozowanie odejść klientów.
- Finanse i bankowość: Sektor finansowy od dawna polega na data mining w celu oceny ryzyka kredytowego (credit scoring), wykrywania prania brudnych pieniędzy (AML) i identyfikacji fałszywych transakcji w czasie rzeczywistym.
- Opieka zdrowotna: Analiza danych medycznych pomaga w przewidywaniu ognisk chorób, diagnozowaniu schorzeń na wczesnym etapie (np. Na podstawie obrazów medycznych), personalizacji leczenia oraz optymalizacji zarządzania szpitalem.
- Produkcja: W przemyśle data mining jest kluczowy dla tzw. Konserwacji predykcyjnej (predictive maintenance), która pozwala przewidywać awarie maszyn, zanim do nich dojdzie, minimalizując przestoje i koszty napraw.
- Telekomunikacja: Firmy telekomunikacyjne analizują ogromne ilości danych o połączeniach i wykorzystaniu sieci, aby optymalizować jej działanie, zapobiegać awariom i identyfikować klientów, którzy z największym prawdopodobieństwem zmienią operatora.
Wyzwania i etyczne aspekty eksploracji danych
Mimo ogromnych korzyści, data mining niesie ze sobą również istotne wyzwania i dylematy etyczne, których nie można ignorować.
Jakość danych: Jak już wspomniano, niska jakość danych wejściowych prowadzi do bezwartościowych wyników. Zapewnienie czystości, kompletności i spójności danych jest stałym wyzwaniem.
Prywatność i bezpieczeństwo: Proces ten często wymaga analizy wrażliwych danych osobowych. Konieczne jest stosowanie technik anonimizacji i rygorystyczne przestrzeganie przepisów o ochronie danych, takich jak RODO/GDPR, aby chronić prywatność jednostek.
Uprzedzenia (bias): Algorytmy uczą się na podstawie danych historycznych. Jeśli te dane odzwierciedlają istniejące w społeczeństwie uprzedzenia (np. Rasowe, płciowe), model może je nie tylko powielić, ale nawet wzmocnić. Może to prowadzić do dyskryminujących decyzji, np. W procesie rekrutacji czy przyznawania kredytów.
Interpretowalność modeli: Niektóre zaawansowane modele, jak głębokie sieci neuronowe, działają jak „czarne skrzynki” (black box). Generują bardzo dokładne predykcje, ale trudno jest zrozumieć, na jakiej podstawie podjęły konkretną decyzję. W wielu dziedzinach (np. Medycynie, finansach) możliwość wyjaśnienia decyzji modelu jest wymogiem prawnym i etycznym.
Zakończenie
Data mining to znacznie więcej niż tylko technologia czy zbiór algorytmów. To ustrukturyzowana metodologia, która łączy w sobie wiedzę biznesową, statystykę i informatykę, aby przekształcić surowe dane w jeden z najważniejszych strategicznych aktywów organizacji. Proces ten, realizowany według sprawdzonych standardów takich jak CRISP-DM, pozwala firmom nie tylko lepiej rozumieć swoją przeszłość, ale przede wszystkim świadomie kształtować przyszłość. Od personalizacji marketingu, przez wykrywanie oszustw, aż po przewidywanie awarii maszyn – zastosowania data mining są wszechobecne i stale się rozwijają.
W dobie rosnącej konkurencji i cyfryzacji, zdolność do efektywnego odkrywania wiedzy z danych przestaje być opcją, a staje się koniecznością. Organizacje, które zainwestują w kompetencje i narzędzia do prowadzenia zaawansowanej eksploracji danych, będą w stanie podejmować lepsze, szybsze i bardziej trafne decyzje, zostawiając konkurencję daleko w tyle. W świecie, w którym dane są nową ropą, data mining Jest rafinerią, która zamienia surowiec w cenne paliwo napędzające wzrost i innowacje.
Zobacz więcej:
- Czym jest feed i jak go efektywnie wykorzystać w marketingu?
- Wirtualny asystent: Klucz do efektywności w biznesie
- Akt o rynkach cyfrowych (DMA): Co musisz wiedzieć o nowych zasadach UE
- Meta description: kompletny przewodnik po skutecznym opisie
- Cloaking: co to jest i dlaczego jest to technika black hat SEO?
Dodaj komentarz