

Crawler, bot, spider – czym są i jak działają w internecie?
Internet to niewyobrażalnie wielka, rozproszona biblioteka, w której każdego dnia przybywają miliony nowych książek, artykułów i notatek. Jak w tym chaosie odnaleźć informację, której szukamy? Odpowiedź kryje się w niestrudzonej pracy niewidzialnych robotników cyfrowego świata – programów znanych jako crawlery, boty i spidery. Choicons nie widzimy ich na co dzień, to właśnie one stanowią fundament działania wyszukiwarek internetowych takich jak Google, a co za tym idzie – klucz do widoczności każdej strony w sieci. Zrozumienie, czym jest crawler I jak funkcjonuje, to dziś absolutna podstawa dla każdego marketera, specjalisty SEO i właściciela biznesu online. W tym artykule zanurzymy się w świat tych cyfrowych eksploratorów, by dokładnie wyjaśnić, kim są, jak pracują i dlaczego ich działalność ma tak fundamentalne znaczenie dla Twojej strategii marketingowej.
Definicje podstawowych pojęć: crawler, bot i spider
Choć w codziennym języku marketingu internetowego terminy te często używane są zamiennie, warto poznać subtelne różnice między nimi, aby w pełni zrozumieć ich naturę i funkcje.
Bot – najszersze pojęcie
Słowo „bot” jest skrótem od „robot” i odnosi się do dowolnego oprogramowania zaprojektowanego do automatyzacji określonych zadań. Jest to pojęcie nadrzędne. Boty mogą wykonywać niezwykle szeroki wachlarz czynności – od odpowiadania na pytania klientów na czacie (chatboty), przez monitorowanie cen w sklepach internetowych, aż po publikowanie treści w mediach społecznościowych. Botem będzie więc zarówno program indeksujący strony dla Google, jak i ten, który próbuje masowo zakładać konta na forum internetowym. Kluczową cechą bota jest automatyzacja – wykonuje on powtarzalne zadania znacznie szybciej i wydajniej niż człowiek.
Spider (pająk) – analogia do sieci
Termin „spider” (pająk) jest bardziej specyficzny i stanowi doskonałą metaforę działania programów indeksujących. Internet, ze swoją strukturą połączonych ze sobą stron (linków), przypomina gigantyczną pajęczą sieć (World Wide Web). Spider to bot, który „pełza” po tej sieci, przemieszczając się od jednego linku do drugiego, dokładnie tak, jak pająk porusza się po swoich niciach. Nazwa ta świetnie obrazuje metodę odkrywania nowych zakątków internetu.
Crawler – techniczny i najpopularniejszy termin
Crawler (Z ang. „to crawl” – pełzać, czołgać się) to obecnie najczęściej stosowany i najbardziej techniczny termin na określenie bota, którego głównym zadaniem jest systematyczne przeglądanie internetu w celu zbierania danych. W kontekście wyszukiwarek internetowych, głównym celem crawlera jest odkrywanie nowych i zaktualizowanych stron internetowych, a następnie przekazywanie zebranych informacji do dalszego przetworzenia, czyli indeksacji. W praktyce, mówiąc o botach Google, Bing czy innych wyszukiwarek, najczęściej użyjemy właśnie słowa crawler. W tym artykule będziemy traktować terminy „crawler” i „spider” jako synonimy, odnoszące się do specyficznego rodzaju bota odpowiedzialnego za przeglądanie sieci.
Jak dokładnie działa crawler? Krok po kroku
Proces działania crawlera, choć w swojej istocie prosty, w praktyce jest niezwykle złożonym i zoptymalizowanym algorytmem. Można go jednak podzielić na kilka logicznych etapów, które powtarzane są w nieskończonej pętli, miliardy razy na dobę.
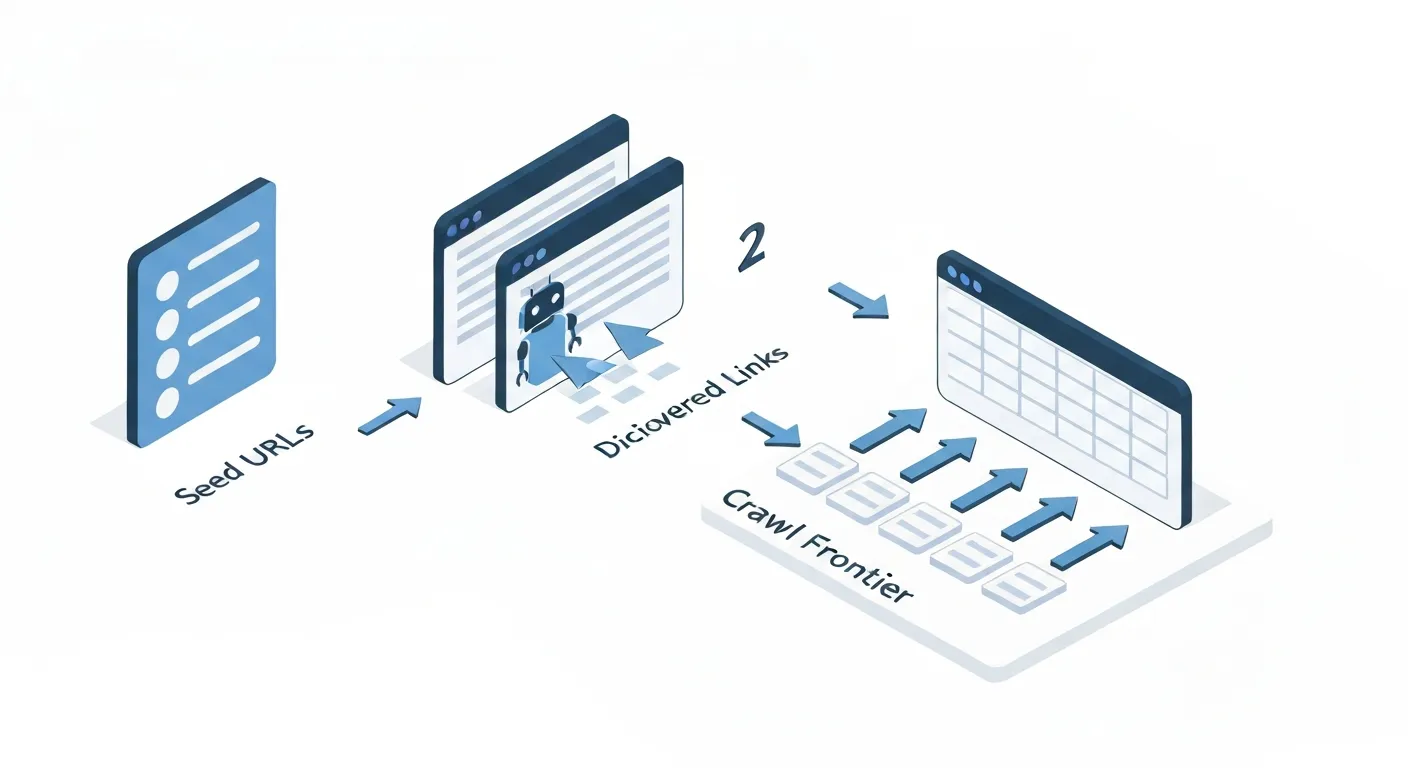
- Rozpoczęcie od listy początkowej (Seed URLs)
Crawler nie zaczyna swojej pracy w przypadkowym miejscu. Dysponuje on początkową listą adresów URL, zwanych „seed URLs”. Są to zazwyczaj adresy dużych, zaufanych i często aktualizowanych stron internetowych, które zawierają mnóstwo linków do innych witryn. Lista ta jest wynikiem wcześniejszych cykli crawlowania oraz danych historycznych. - Odwiedziny i analiza strony
Następnie crawler Wybiera adres URL z listy i „odwiedza” go, pobierając całą jego zawartość – przede wszystkim kod HTML. W tym momencie program zachowuje się jak przeglądarka internetowa, ale bez interfejsu graficznego. Analizuje kod strona po stronie, szukając kluczowych elementów. - Odkrywanie i ekstrakcja linków
Najważniejszym znaleziskiem dla crawlera na danej stronie są hiperłącza (tagi<a href="...">). Każdy znaleziony link do innej strony (wewnętrznej lub zewnętrznej), który nie był mu dotąd znany, jest traktowany jako potencjalne nowe miejsce do odwiedzenia. - Dodawanie do kolejki (Crawl Frontier)
Wszystkie nowo odkryte adresy URL są dodawane do ogromnej listy zadań do wykonania, nazywanej „kolejką” lub „granicą indeksowania” (crawl frontier). To gigantyczna baza danych zawierająca adresy, które czekają na swoją kolej do odwiedzenia. - Priorytetyzacja i pobieranie
Kolejka ta nie jest prosta listą „kto pierwszy, ten lepszy”. Zaawansowane algorytmy ustalają priorytety. Strony o wysokim autorytecie (np. Mierzone wskaźnikiem PageRank), często aktualizowane lub te, które w przeszłości dostarczały wartościowych treści, będą odwiedzane częściej. Crawler Pobiera stronę z kolejki o najwyższym priorytecie i wraca do kroku drugiego. - Przekazanie danych do indeksu
Równocześnie z odkrywaniem linków, crawler Zbiera kluczowe informacje o treści strony: tekst, nagłówki (H1, H2 itd.), tytuły (title), opisy meta, atrybuty alt obrazków i wiele innych. Te dane są następnie przekazywane do innego potężnego systemu wyszukiwarki – indeksatora. Indeksator przetwarza te informacje, porządkuje je i umieszcza w gigantycznej bazie danych (indeksie), dzięki czemu strona może pojawić się w wynikach wyszukiwania. - Renderowanie stron (JavaScript)
Współczesne strony internetowe często opierają się na JavaScript do generowania treści. Proste pobranie kodu HTML może nie wystarczyć, aby zobaczyć pełną zawartość. Dlatego zaawansowane crawlery, takie jak Googlebot, potrafią również renderować strony – czyli uruchomić skrypty JavaScript i poczekać, aż treść dynamicznie pojawi się na stronie, podobnie jak robi to ludzki użytkownik w swojej przeglądarce. To kluczowe dla prawidłowej indeksacji nowoczesnych witryn.
Ten cykl powtarza się bez końca, co pozwala wyszukiwarkom na bieżąco aktualizować swój obraz internetu, odkrywać nowe strony i usuwać te, które przestały istnieć.
Najważniejsze crawlery w internecie i ich rola
Każda wyszukiwarka i wiele dużych narzędzi analitycznych posiada własne, dedykowane crawlery. Identyfikują się one za pomocą specjalnego nagłówka zwanego „User-Agent”. Oto najważniejsi gracze na tym rynku:
- Googlebot: Bez wątpienia najważniejszy i najbardziej aktywny crawler Na świecie. Google utrzymuje kilka jego wersji, z których najważniejsze to Googlebot Desktop i Googlebot Smartphone. Ze względu na politykę Mobile-First Indexing, to właśnie wersja mobilna jest podstawowym crawlerem dla większości stron. Jego aktywność jest kluczowa dla widoczności w najpopularniejszej wyszukiwarce świata.
- Bingbot: To crawler Należący do Microsoftu, odpowiedzialny za indeksowanie stron dla wyszukiwarki Bing. Chociaż udział Binga w rynku jest znacznie mniejszy niż Google, wciąż generuje on znaczący ruch, zwłaszcza w niektórych krajach i segmentach demograficznych.
- DuckDuckBot: Crawler wyszukiwarki DuckDuckGo, która stawia na prywatność użytkowników. Jego działanie jest kluczowe dla widoczności w tej coraz popularniejszej alternatywie dla Google.
- Baiduspider: Robot indeksujący chińskiego giganta wyszukiwania, Baidu. Jeśli Twój biznes celuje w rynek chiński, optymalizacja pod kątem tego crawlera jest absolutnie niezbędna.
- YandexBot: Odpowiednik Googlebota dla Yandex, dominującej wyszukiwarki w Rosji i kilku innych krajach Europy Wschodniej.
- Crawlery narzędzi SEO: Istnieje też cała armia botów należących do popularnych narzędzi marketingowych. Przykłady to AhrefsBot (Ahrefs), SEMrushBot (SEMrush) czy Rogerbot (Moz). Te crawlery nie budują publicznego indeksu, lecz zbierają dane na potrzeby analizy linków zwrotnych, audytów technicznych SEO i monitorowania pozycji, z których korzystają specjaliści na całym świecie.
Crawler a SEO – dlaczego to kluczowa relacja?

Z perspektywy optymalizacji pod wyszukiwarki (SEO), relacja ze crawlerami jest absolutnie fundamentalna. Można mieć najlepszą treść i najpiękniejszą stronę, ale jeśli crawler Nie będzie w stanie jej skutecznie znaleźć, przeczytać i zrozumieć, cały wysiłek pójdzie na marne. Oto kluczowe aspekty tej zależności:
Indeksowalność – warunek istnienia w Google
Podstawowa zasada brzmi: jeśli strona nie zostanie scrawlowana, nie zostanie zaindeksowana. Jeśli nie zostanie zaindeksowana, nigdy nie pojawi się w wynikach wyszukiwania. Dlatego pierwszym krokiem w każdym audycie SEO jest upewnienie się, że crawlery mają swobodny dostęp do najważniejszych zasobów serwisu.
Budżet indeksowania (Crawl Budget)
Wyszukiwarki nie mają nieskończonych zasobów. Każdej witrynie przydzielają tzw. „budżet indeksowania” – jest to przybliżona liczba stron, jaką crawler Jest w stanie i chce odwiedzić na danej domenie w określonym czasie. Na budżet ten wpływają takie czynniki jak autorytet domeny, szybkość ładowania strony oraz to, jak często publikowane są na niej nowe, wartościowe treści. Zadaniem specjalisty SEO jest maksymalne wykorzystanie tego budżetu, kierując crawlery na najważniejsze podstrony i blokując im dostęp do tych nieistotnych (np. Strony z wynikami filtrowania, wersje do druku, panele logowania).
Optymalizacja pod crawlery (Techniczne SEO)
Wiele działań w ramach technicznego SEO ma na celu ułatwienie pracy crawlerom. Do najważniejszych należą:
- Plik robots.txt: To prosty plik tekstowy umieszczony w głównym katalogu strony, który działa jak zbiór instrukcji dla botów. Można w nim wskazać, których części serwisu crawlery nie powinny odwiedzać (dyrektywa
Disallow). - Mapa strony (sitemap.xml): To plik w formacie XML, który zawiera listę wszystkich ważnych adresów URL w witrynie. Działa jak mapa, którą podajemy crawlerowi, aby upewnić się, że nie pominie żadnego istotnego zakątka.
- Struktura linkowania wewnętrznego: Logiczne i przemyślane linkowanie pomiędzy podstronami w ramach jednego serwisu nie tylko pomaga użytkownikom, ale również prowadzi crawlera za rękę, pokazując mu hierarchię i powiązania tematyczne między treściami.
- Szybkość ładowania strony: Im szybciej strona odpowiada na żądanie crawlera, tym więcej podstron jest on w stanie odwiedzić w ramach przydzielonego budżetu. Szybka strona to efektywniejsze crawlowanie.
- Zarządzanie błędami: Strony zwracające błędy (np. 404 – Nie znaleziono, 5xx – Błąd serwera) marnują cenny budżet indeksowania. Regularne monitorowanie i naprawianie takich błędów jest kluczowe.
Jak kontrolować i monitorować aktywność crawlerów na stronie?
Na szczęście nie jesteśmy skazani na domysły. Istnieją konkretne narzędzia, które pozwalają śledzić, jak crawlery postrzegają naszą stronę i wchodzą z nią w interakcję.
Google Search Console
To darmowe i absolutnie niezbędne narzędzie od Google dla każdego właściciela strony. W kontekście crawlerów, najważniejsze są w nim następujące raporty:
- Raport „Statystyki indeksowania”: Pokazuje szczegółowe dane na temat aktywności Googlebota na Twojej stronie. Dowiesz się z niego, ile żądań crawler Wysłał w ostatnim czasie, jaki był średni czas odpowiedzi serwera i jakie kody stanu HTTP najczęściej napotykał (np. OK 200, błędy 404).
- Raport „Stan w indeksie”: Informuje o tym, które strony z Twojej witryny znajdują się w indeksie Google, a które zostały z jakiegoś powodu wykluczone (np. Przez blokadę w pliku robots.txt, tag „noindex” czy z powodu duplikacji treści).
- Narzędzie do sprawdzania adresów URL: Pozwala na ręczne sprawdzenie konkretnego adresu URL i zobaczenie, jak widzi go Google. Można tam również poprosić o jego ponowne scrawlowanie, co jest przydatne po wprowadzeniu ważnych zmian.
Analiza logów serwera
To bardziej zaawansowana metoda, dająca najpełniejszy obraz aktywności botów. Pliki logów serwera zapisują każde pojedyncze żądanie wysłane do serwera – od użytkowników i od wszystkich botów (nie tylko Googlebota). Analiza tych danych pozwala zidentyfikować, które strony są crawlowane najczęściej, czy boty nie marnują czasu na nieistotne zasoby oraz czy nie mamy problemu z niechcianymi, „złymi” botami.
„Dobre” i „złe” boty – nie każdy crawler jest przyjacielem
Warto pamiętać, że świat botów ma swoją jasną i ciemną stronę. Podczas gdy crawlery wyszukiwarek i narzędzi SEO są pożądanymi gośćmi, istnieje cała masa botów o szkodliwych lub co najmniej irytujących zamiarach.
Dobre boty (Good Bots)
To wszystkie te programy, których działanie przynosi jakąś korzyść. Należą do nich wspomniane już crawlery wyszukiwarek (indeksują naszą treść), boty narzędzi analitycznych (dostarczają danych do optymalizacji), a także boty monitorujące dostępność strony (sprawdzające, czy witryna działa poprawnie).
Złe boty (Bad Bots)
Ta kategoria jest niestety bardzo szeroka. Do złych botów zaliczamy:
- Scrapery: Boty, których jedynym celem jest masowe kopiowanie treści z Twojej strony w celu umieszczenia jej gdzie indziej (kradzież contentu).
- Spamboty: Programy automatycznie wypełniające formularze kontaktowe, dodające spamerskie komentarze na blogu lub zakładające fałszywe konta użytkowników.
- Boty do ataków: Wykorzystywane do przeprowadzania ataków typu DDoS (obciążających serwer ogromną liczbą zapytań) lub próbujących odgadnąć hasła do paneli administracyjnych.
Ochrona przed złymi botami to osobny, szeroki temat, obejmujący takie rozwiązania jak systemy CAPTCHA, firewalle aplikacyjne (WAF) czy usługi takie jak Cloudflare, które potrafią filtrować szkodliwy ruch, zanim dotrze on do serwera.
Podsumowanie: dlaczego crawler to twój najważniejszy gość
Crawlery, boty i spidery to nie jest już wiedza tajemna zarezerwowana dla inżynierów oprogramowania. To fundamentalne elementy ekosystemu internetowego, których zrozumienie jest warunkiem skutecznego marketingu cyfrowego. Stanowią one most pomiędzy treścią, którą tworzysz, a użytkownikiem, który jej poszukuje. Bez efektywnej pracy crawlera, Twoja strona pozostaje niewidzialną wyspą na bezkresnym oceanie internetu. Dlatego dbanie o „zdrowie techniczne” witryny, ułatwianie botom pracy poprzez czytelną strukturę, szybkie ładowanie i jasne dyrektywy, to nie jest techniczny dodatek, a strategiczna inwestycja w widoczność. Pamiętaj, że pierwszym i najważniejszym „użytkownikiem” Twojej strony jest właśnie crawler. Jeśli zadbasz o jego pozytywne doświadczenia, z pewnością odwdzięczy Ci się lepszą pozycją w wynikach wyszukiwania.
Zobacz więcej:
- Repurposing: jak dać drugie życie swoim treściom i zwielokrotnić ich zasięg?
- Net Promoter Score: co to jest, jak go mierzyć i dlaczego jest ważny?
- Employee advocacy: jak zaangażować pracowników w promocję twojej marki
- Aktualizacja algorytmu Google: co musisz wiedzieć, aby nie stracić widoczności
- CPI (Cost Per Install): Kluczowy wskaźnik w marketingu mobilnym
Dodaj komentarz